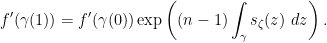Before we begin, I want to fuss around with model theory again. Recall that if  is a nonstandard complex number, then
is a nonstandard complex number, then 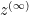 denotes the standard part of , if it exists. We previously defined what it meant for a nonstandard random variable to be infinitesimal in distribution. One can define something similar for any metrizable space with a notion of
denotes the standard part of , if it exists. We previously defined what it meant for a nonstandard random variable to be infinitesimal in distribution. One can define something similar for any metrizable space with a notion of  , where
, where  is infinitesimal provided that
is infinitesimal provided that 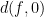 is. For example, a nonstandard random variable
is. For example, a nonstandard random variable  is infinitesimal in
is infinitesimal in  if for every compact set
if for every compact set  that can take values in,
that can take values in, 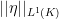 is infinitesimal, since is metrizable with
is infinitesimal, since is metrizable with

whenever  is a compact exhaustion. If is nonstandard,
is a compact exhaustion. If is nonstandard,  is infinitesimal in some metrizable space, and
is infinitesimal in some metrizable space, and  is standard, then we call the standard part of in
is standard, then we call the standard part of in  ; then the standard part is unique since metrizable spaces are Hausdorff.
; then the standard part is unique since metrizable spaces are Hausdorff.
If the metrizable space is compact, the case that we will mainly be interested in, then the standard part exists. This is a point that we will use again and again. Passing to the cheap perspective, this says that if is a compact metric space and  is a sequence in , then there is a which is approximates
is a sequence in , then there is a which is approximates  infinitely often, but that’s just the Bolzano-Weierstrass theorem. Last time used Prokohov’s theorem to show that if
infinitely often, but that’s just the Bolzano-Weierstrass theorem. Last time used Prokohov’s theorem to show that if  is a nonstandard tight random variable, then has a standard part
is a nonstandard tight random variable, then has a standard part  in distribution.
in distribution.
We now restate and prove Proposition 9 from the previous post.
Theorem 1 (distribution of random zeroes) Let  be a nonstandard natural, a monic polynomial of degree with all zeroes in
be a nonstandard natural, a monic polynomial of degree with all zeroes in  , and let
, and let ![{a \in [0, 1]}](https://s0.wp.com/latex.php?latex=%7Ba+%5Cin+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be a zero of . Suppose that
be a zero of . Suppose that 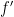 has no zeroes in
has no zeroes in 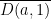 . Let
. Let  be a random zero of and
be a random zero of and  a random zero of . Then:
a random zero of . Then:
- If
 (case zero), then
(case zero), then  and
and 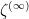 are identically distributed and almost surely lie in the curve
are identically distributed and almost surely lie in the curve
![\displaystyle C = \{e^{i\theta}: 2\theta \in [\pi, 3\pi]\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C+%3D+%5C%7Be%5E%7Bi%5Ctheta%7D%3A+2%5Ctheta+%5Cin+%5B%5Cpi%2C+3%5Cpi%5D%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
In particular,  in probability. Moreover, for every compact set
in probability. Moreover, for every compact set 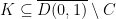 ,
,

- If
 (case one), then is uniformly distributed on the unit circle
(case one), then is uniformly distributed on the unit circle 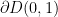 and is almost surely zero. Moreover,
and is almost surely zero. Moreover,

1. Moment-generating functions and balayage
We first show that and have equal moment-generating functions in a suitable sense.
To do this, we first show that they have the same logarithmic potential. Let be a random variable such that  almost surely (that is, is almost surely bounded). Then the logarithmic potential
almost surely (that is, is almost surely bounded). Then the logarithmic potential

is defined almost everywhere as we discussed last time, and is harmonic outside of the essential range of .
Lemma 2 Let be a nonstandard, almost surely bounded, random complex number. Then the standard part of  is
is 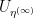 according to the topology of under Lebesgue measure.
according to the topology of under Lebesgue measure.
Proof: We pass to the cheap perspective. If we instead have a random sequence of  and
and  in distribution, then
in distribution, then 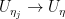 in , since up to a small error in we can replace
in , since up to a small error in we can replace 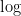 with a test function
with a test function  ; one then has
; one then has

where  in the weak topology of measures,
in the weak topology of measures, 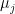 is the distribution of ,
is the distribution of ,  is the distribution of , and is a compact set equipped with Lebesgue measure.
is the distribution of , and is a compact set equipped with Lebesgue measure. 
Lemma 3 For every  , we have
, we have

In particular,  .
.
Proof: By definition, 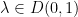 , so
, so  . Now
. Now  is a disc with diameter
is a disc with diameter ![{T([|z| - 1, |z| + 1])}](https://s0.wp.com/latex.php?latex=%7BT%28%5B%7Cz%7C+-+1%2C+%7Cz%7C+%2B+1%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) where
where  is a rotation around the origin. Taking reciprocals preserves discs and preserves , so
is a rotation around the origin. Taking reciprocals preserves discs and preserves , so 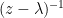 sits inside a disc
sits inside a disc  with a diameter
with a diameter ![{T[(|z|+1)^{-1}, (|z|-1)^{-1}]}](https://s0.wp.com/latex.php?latex=%7BT%5B%28%7Cz%7C%2B1%29%5E%7B-1%7D%2C+%28%7Cz%7C-1%29%5E%7B-1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then is convex, so the expected value of is also
. Then is convex, so the expected value of is also 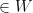 . Therefore the Stieltjes transform
. Therefore the Stieltjes transform
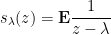
satisfies  . In particular,
. In particular,
![\displaystyle \log |s_\lambda(z)| \in \left[\log \frac{1}{|z| + 1}, \log \frac{1}{|z| - 1}\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog+%7Cs_%5Clambda%28z%29%7C+%5Cin+%5Cleft%5B%5Clog+%5Cfrac%7B1%7D%7B%7Cz%7C+%2B+1%7D%2C+%5Clog+%5Cfrac%7B1%7D%7B%7Cz%7C+-+1%7D%5Cright%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
But we showed that

almost everywhere last time. This implies that for almost every ,

but all terms here are continuous so we can promote this to a statement that holds for every . In particular,
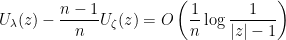
hence

Since  while
while 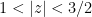 ,
, 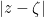 is bounded from above and below by a constant times
is bounded from above and below by a constant times  . Therefore the same holds of its logarithm
. Therefore the same holds of its logarithm  , which is bounded from above and below by a constant times
, which is bounded from above and below by a constant times 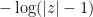 . This implies the first claim.
. This implies the first claim.
To derive the second claim from the first, we use the previous lemma, which implies that we must show that

in . But this follows since  is integrable in two dimensions.
is integrable in two dimensions.
Lemma 4 Let be an almost surely bounded random variable. Then
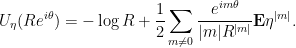
Proof: One has the Taylor series
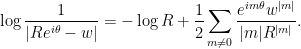
Indeed, by rescaling and using 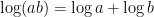 , we may assume
, we may assume 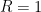 . The summands expand as
. The summands expand as

and the imaginary parts all cancel by symmetry about . Using the symmetry about again we get

This equals the left-hand side as long as  . Taking expectations and commuting the expectation with the sum using Fubini’s theorem (since is almost surely bounded), we see the claim.
. Taking expectations and commuting the expectation with the sum using Fubini’s theorem (since is almost surely bounded), we see the claim.
Lemma 5 For all 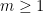 , one has
, one has

In particular, and have identical moments.
Proof: If we take  then we conclude that
then we conclude that

The left-hand side is a Fourier series, and by uniqueness of Fourier series it holds that for every  ,
,

This gives a bound on the difference of moments

which is only possible if the moments of and are identical. The left-hand side doesn’t depend on  , but if
, but if 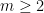 ,
, 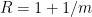 , then
, then  and
and  so the claim holds. On the other hand, if
so the claim holds. On the other hand, if  then this claim still holds, since we showed last time that
then this claim still holds, since we showed last time that

and obviously  .
.
Here I was puzzled for a bit. Surely if two random variables have the same moment-generating function then they are identically distributed! But, while we can define the moment-generating function of a random variable as a formal power series  , it is not true that has to have a positive radius of convergence, in which case the inverse Laplace transform of is ill-defined. Worse, the circle is not simply connected, and in case one, we have to look at a uniform distribution on the circle, whose moments therefore aren’t going to points on the circle, so the moment-generating function doesn’t tell us much.
, it is not true that has to have a positive radius of convergence, in which case the inverse Laplace transform of is ill-defined. Worse, the circle is not simply connected, and in case one, we have to look at a uniform distribution on the circle, whose moments therefore aren’t going to points on the circle, so the moment-generating function doesn’t tell us much.
2. Balayage
We recall the definition of the Poisson kernel  :
:

whenever 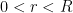 is a radius. Convolving the Poisson kernel against a continuous function on
is a radius. Convolving the Poisson kernel against a continuous function on  solves the Dirichlet problem of
solves the Dirichlet problem of  with boundary data .
with boundary data .
Definition 6 Let 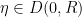 be a random variable. The balayage of is
be a random variable. The balayage of is

Balayage is a puzzling notion. First, the name refers to a hair-care technique, which is kind of unhelpful. According to Tao, we’re supposed to interpret balayage as follows.
If  is an initial datum for Brownian motion
is an initial datum for Brownian motion  , then
, then  is the probability density of the first location
is the probability density of the first location  where passes through . Tao asserts this without proof, but conveniently, this was a problem in my PDE class last semester. The idea is to approximate
where passes through . Tao asserts this without proof, but conveniently, this was a problem in my PDE class last semester. The idea is to approximate  by the lattice
by the lattice  , which we view as a graph where each vertex has degree
, which we view as a graph where each vertex has degree  , with one edge to each of the vertices directly above, below, left, and right of it. Then the Laplacian on is approximated by the graph Laplacian on
, with one edge to each of the vertices directly above, below, left, and right of it. Then the Laplacian on is approximated by the graph Laplacian on  , and Brownian motion is approximated by the discrete-time stochastic process wherein a particle starts at the vertex that best approximates
, and Brownian motion is approximated by the discrete-time stochastic process wherein a particle starts at the vertex that best approximates  and at each stage has a
and at each stage has a  chance of moving to each of the vertices adjacent to its current position.
chance of moving to each of the vertices adjacent to its current position.
So suppose that and are actually vertices of . The probability density 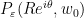 is harmonic in with respect to the graph Laplacian since it is the mean of
is harmonic in with respect to the graph Laplacian since it is the mean of  as ranges over the adjacent vertices to ; therefore it remains harmonic as we take
as ranges over the adjacent vertices to ; therefore it remains harmonic as we take  . The boundary conditions follow similarly.
. The boundary conditions follow similarly.
Now if is a random initial datum for Brownian motion which starts in  , the balayage of is again a probability density on that records where one expects the Brownian motion to escape, but this time the initial datum is also random.
, the balayage of is again a probability density on that records where one expects the Brownian motion to escape, but this time the initial datum is also random.
I guess the point is that balayage serves as a substitute for the moment-generating function in the event that the latter is just a formal power series. We want to be able to use analytic techniques on the moment-generating function, but we can’t, so we just use balayage instead.
Let  be the balayage of . Since is bounded, we can use Fubini’s theorem to commute the expectation with the sum and see that
be the balayage of . Since is bounded, we can use Fubini’s theorem to commute the expectation with the sum and see that

provided that  . It will be convenient to rewrite this in the form
. It will be convenient to rewrite this in the form

so is uniquely determined by the moment-generating function of . In particular, and have identical balayage, and one has a bound

We claim that

which implies the bound

To see this, we discard the term since , which implies that

Up to a constant factor we may assume that the logarithms are base  in which case we get a bound
in which case we get a bound

The constant is absolute since ![{R \in (1, 3/2]}](https://s0.wp.com/latex.php?latex=%7BR+%5Cin+%281%2C+3%2F2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
By the integral test, we get a bound

Using the bound

for any  and the change of variable
and the change of variable 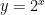 (thus
(thus  ), we get a bound
), we get a bound

since the  error in the exponent can’t affect the exponential decay of the integral in
error in the exponent can’t affect the exponential decay of the integral in  . Since we certainly have
. Since we certainly have

this is a suitable tail bound.
To complete the proof of the claim we need to bound the main term. To this end we bound
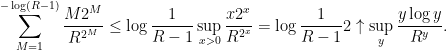
Here  denotes exponentiation. Now if
denotes exponentiation. Now if 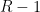 is small enough (say
is small enough (say 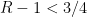 ), this supremum will be attained when
), this supremum will be attained when  , thus
, thus  . Therefore
. Therefore

Luckily 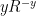 is easy to differentiate: its critical point is
is easy to differentiate: its critical point is  . This gives
. This gives

so
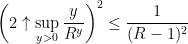
which was the bound we needed, and proves the claim. Maybe there’s an easier way to do this, because Tao says the claim is a trivial consequence of dyadic decomposition.
Let’s interpret the bound that we just proved. Well, if the balayage of is supposed to describe the point on the circle at which a Brownian motion with random initial datum escapes, a bound on a difference of two balyages should describe how the trajectories diverge after escaping. In this case, the divergence is infinitesimal, but at different speeds depending on . As  , our infinitesimal divergence gains a positive standard part, while if stays close to
, our infinitesimal divergence gains a positive standard part, while if stays close to 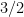 , the divergence remains infinitesimal. This makes sense, since if we take a bigger circle we forget more and more about the fact that
, the divergence remains infinitesimal. This makes sense, since if we take a bigger circle we forget more and more about the fact that  are not the same random variable, since Brownian motion has more time to “forget more stuff” as it just wanders around aimlessly. So in the regime where is close to , it is reasonable to take standard parts and pass to and , while in the regime where is close to
are not the same random variable, since Brownian motion has more time to “forget more stuff” as it just wanders around aimlessly. So in the regime where is close to , it is reasonable to take standard parts and pass to and , while in the regime where is close to  this costs us dearly.
this costs us dearly.
3. Case zero
Suppose that  is infinitesimal.
is infinitesimal.
We showed last time that 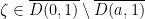 , so
, so  is infinitesimal. Therefore
is infinitesimal. Therefore  almost surely.
almost surely.
I think there’s a typo here, because Tao lets range over 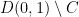 and considers points
and considers points  , which don’t exist since
, which don’t exist since 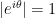 while every point in
while every point in 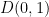 has
has  . I think this can be fixed by taking closures, which is what I do in the next lemma.
. I think this can be fixed by taking closures, which is what I do in the next lemma.
Tao proves a “qualitative” claim and then says that by repeating the argument and looking out for constants you can get a “quantitative” version which is what he actually needs. I’m just going to prove the quantitative argument straight-up. The idea is that if is a compact set which misses  and
and  then a Brownian motion with initial datum will probably escape through an arc
then a Brownian motion with initial datum will probably escape through an arc  which is close to , but is not close to so a Brownian motion which starts at will probably not escape through . Therefore
which is close to , but is not close to so a Brownian motion which starts at will probably not escape through . Therefore 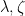 have very different balayage, even though the difference in their balayage was already shown to be infinitesimal.
have very different balayage, even though the difference in their balayage was already shown to be infinitesimal.
I guess this shows the true power of balayage: even though the moment-generating function is “just” a formal power series, we know that the essential supports of must “look like each other” up to rescaling in radius. This still holds in case one, where one of them is a circle and the other is the center of the circle. Either way, you get the same balayage, since whether you start at some point on a circle or you start in the center of the circle, if you’re a Brownian motion you will exhibit the same long-term behavior.
In the following lemmata, let  be a compact set. The set
be a compact set. The set  is compact since it is the preimage of a compact set, so contained a compact interval
is compact since it is the preimage of a compact set, so contained a compact interval 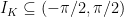 .
.
Lemma 7 One has

Proof: Since is compact the minimum is attained. Let be the minimum. Since is a real-valued harmonic function in , thus

the maximum principle implies that the worst case is when meets 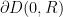 and
and  , say
, say 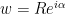 . Then
. Then
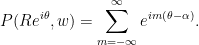
Of course this is just a formal power series and doesn’t make much sense. But if instead 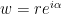 where
where 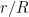 is very small depending on a given
is very small depending on a given  , then, after discarding quadratic terms in ,
, then, after discarding quadratic terms in ,

This follows since in general
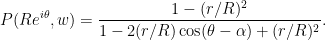
Now

since the integrand is maximized when  , in which case the integrand evaluates to the measure of
, in which case the integrand evaluates to the measure of 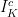 , which is
, which is  since
since  and
and  has positive measure. Therefore
has positive measure. Therefore
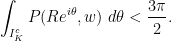
On the other hand, for any one has

so this implies gives a lower bound on the integral over .
Lemma 8 If then
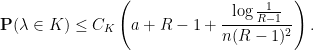
Proof: Let  in the previous lemma, conditioning on the event , to see that
in the previous lemma, conditioning on the event , to see that

where  . Taking expectations and dividing by the probability that , we can use Fubini’s theorem to deduce
. Taking expectations and dividing by the probability that , we can use Fubini’s theorem to deduce

where  . Applying the bound on
. Applying the bound on 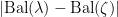 from the section on balayage, we deduce
from the section on balayage, we deduce

We already showed that . So in order to show

which was the bound that we wanted, it suffices to show that for every  such that
such that 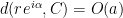 ,
,
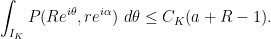
Tao says that “one can show” this claim, but I wasn’t able to do it. I think the point is that under those cirumstances one has 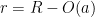 and
and  even as
even as 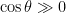 , so we have some control on
, so we have some control on 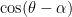 . In fact I was able to compute
. In fact I was able to compute

which suggests that this is the right direction, but the bounds I got never seemed to go anywhere. Someone bug me in the comments if there’s an easy way to do this that I somehow missed.
Now we take  to complete the proof.
to complete the proof.
4. Case one
Suppose that  is infinitesimal. Let be the expected value of (hence also of ). Let
is infinitesimal. Let be the expected value of (hence also of ). Let  be a standard real.
be a standard real.
We first need to go on an excursion to a paper of Dégot, who proves the following theorem:
Lemma 9 One has

Moreover,

I will omit the proof since it takes some complex analysis I’m pretty unfamiliar with. It seems to need Grace’s theorem, which I guess is a variant of one of the many theorems in complex analysis that says that the polynomial image of a disk is kind of like a disk. It also uses some theorem called the Walsh contraction principle that involves polynomials on the projective plane. Curious.
In what follows we will say that an event  is standard-possible if the probability that happens has positive standard part.
is standard-possible if the probability that happens has positive standard part.
Lemma 10 For every ,  is standard-possible. Besides,
is standard-possible. Besides, 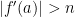 .
.
Proof: Since  almost surely and
almost surely and
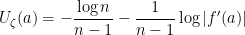
but
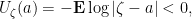
we have

Combining this with the lemma we see that the standard part of  is
is 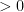 , so
, so

On the other hand,

and since is nonstandard, 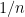 is infinitesimal, so the constant in
is infinitesimal, so the constant in  gets eaten. In particular,
gets eaten. In particular,
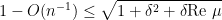
which implies that
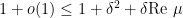
and hence

Since this is true for arbitrary standard  , underspill implies that there is an infinitesimal
, underspill implies that there is an infinitesimal  such that
such that

But  almost surely, and we just showed
almost surely, and we just showed
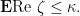
So the claim holds.
We now allow to take the value , thus 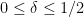 .
.
Lemma 11 One has

and

Moreover,  if
if  , so has no zeroes in that disk.
, so has no zeroes in that disk.
Proof: Since

one has
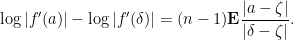
Now  and
and  .
.
Here I drew two unit circles in 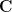 , one entered at the origin and one at (since
, one entered at the origin and one at (since 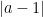 is infinitesimal); is (up to infinitesimal error) in the first circle and out of the second. The rightmost points of intersection between the two circles are on a vertical line which by the Pythagorean theorem is to the left of the vertical line
is infinitesimal); is (up to infinitesimal error) in the first circle and out of the second. The rightmost points of intersection between the two circles are on a vertical line which by the Pythagorean theorem is to the left of the vertical line  , which in turn is to the left of the perpendicular bisector
, which in turn is to the left of the perpendicular bisector 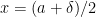
![{[\delta, a]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cdelta%2C+a%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Thus
. Thus  , and if
, and if 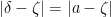 then the real part of is
then the real part of is  . In particular, if the standard real part of is
. In particular, if the standard real part of is 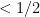 then
then 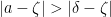 , so
, so 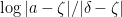 has positive standard part.
has positive standard part.
By the previous lemma, it is standard-possible that the standard real part of is  , so the standard real part of is standard-possibly positive and
, so the standard real part of is standard-possibly positive and  is almost surely nonnegative. Plugging into the above we deduce the existence of a standard absolute constant
is almost surely nonnegative. Plugging into the above we deduce the existence of a standard absolute constant 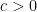 such that
such that

In particular,

Keeping in mind that is nonstandard, this doesn’t necessarily mean that 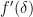 has nonpositive standard part, but it does give a pretty tight bound. Taking a first-order Taylor approximation we get
has nonpositive standard part, but it does give a pretty tight bound. Taking a first-order Taylor approximation we get

But one has
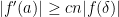
from the Dégot lemma. Clearly this term dominates  so we have
so we have

Since one has a lower bound this implies  is controlled from below by an absolute constant.
is controlled from below by an absolute constant.
We also claim  . In fact, we showed last time that
. In fact, we showed last time that

we want to show that  , so it suffices to show that
, so it suffices to show that  , or in other words that
, or in other words that
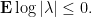
Since 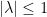 by assumption on , this is trivial. We deduce that
by assumption on , this is trivial. We deduce that
and hence
Now Tao claims that the proof that is similar, if . Since  was a valid choice of we have
was a valid choice of we have 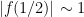 . Since , if
. Since , if  then
then 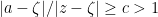 where
where  is an absolute constant. Applying the fact that is standard-possible and
is an absolute constant. Applying the fact that is standard-possible and  is almost surely nonnegative we get
is almost surely nonnegative we get
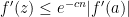
so we indeed have the claim.
We now prove the desired bound

Actually,
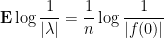
as we proved last time, so the bound  guarantees the claim.4
guarantees the claim.4
In particular

by Fatou’s lemma. So  almost surely. Therefore
almost surely. Therefore 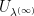 is harmonic on , and we already showed that if
is harmonic on , and we already showed that if 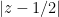 was small enough, thus
was small enough, thus

if was small enough. That implies 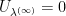 on an open set and hence everywhere. Since
on an open set and hence everywhere. Since

we can plug in  and conclude that all moments of except the zeroth moment are zero. So is uniformly distributed on the unit circle.
and conclude that all moments of except the zeroth moment are zero. So is uniformly distributed on the unit circle.
By overspill, I think one can intuit that if is a random polynomial of high degree which has a zero close to , all zeroes in , and no critical point close to , then sort of looks like

where  is a primitive root of unity of the same degree as . Therefore looks like a cyclotomic polynomial, and therefore should have lots of zeroes close to the unit sphere, in particular close to , a contradiction. This isn’t rigorous but gives some hint as to why this case might be bad.
is a primitive root of unity of the same degree as . Therefore looks like a cyclotomic polynomial, and therefore should have lots of zeroes close to the unit sphere, in particular close to , a contradiction. This isn’t rigorous but gives some hint as to why this case might be bad.
Now one has

and in particular by Fatou’s lemma

But it was almost surely true that  , thus that
, thus that  . So this enforces
. So this enforces  almost surely. In particular, almost surely,
almost surely. In particular, almost surely,

Since  is a contractible curve, its complement is connected. We recall that
is a contractible curve, its complement is connected. We recall that 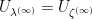 near infinity, and since we already know the distribution of , we can use it to compute
near infinity, and since we already know the distribution of , we can use it to compute  near infinity. Tao says the computation of is a straightforward application of the Newtonian shell theorem; he’s not wrong but I figured I should write out the details.
near infinity. Tao says the computation of is a straightforward application of the Newtonian shell theorem; he’s not wrong but I figured I should write out the details.
For one has

where the 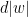 denotes that this is a line integral in rather than in . Translating we get
denotes that this is a line integral in rather than in . Translating we get

which is the integral of the fundamental solution of the Laplace equation over 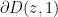 . If
. If  (reasonable since is close to infinity), this implies the integrand is harmonic, so by the mean-value formula one has
(reasonable since is close to infinity), this implies the integrand is harmonic, so by the mean-value formula one has
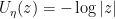
and so this holds for both and 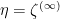 near infinity. But then is harmonic away from , so that implies that
near infinity. But then is harmonic away from , so that implies that

Since the distribution  of is the Laplacian of one has
of is the Laplacian of one has

Therefore 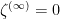 almost surely. In particular, is infinitesimal almost surely. This completes the proof in case one.
almost surely. In particular, is infinitesimal almost surely. This completes the proof in case one.
By the way, I now wonder if when one first learns PDE it would be instructive to think of the fundamental solution of the Laplace equation and the mean-value formulae as essentially a consequence of the classical laws of gravity. Of course the arrow of causation actually points the other way, but we are humans living in a physical world and so have a pretty intuitive understanding of what gravity does, while stuff like convolution kernels seem quite abstract.
Next time we’ll prove a contradiction for case zero, and maybe start on the proof for case one. The proof for case one looks really goddamn long, so I’ll probably skip or blackbox some of it, maybe some of the earlier lemmata, in the interest of my own time.
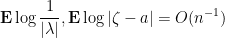


be a compact set. Then
.
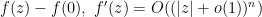
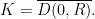
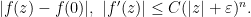
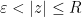

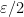


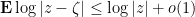




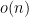


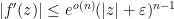

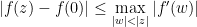
and a standard countable set
such that
, and
is infinitesimal.



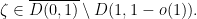

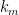




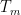


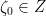
is
is infinitesimal.



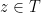



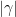
. Then there is a curve

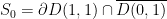
![{[z, w]}](https://s0.wp.com/latex.php?latex=%7B%5Bz%2C+w%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
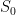
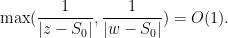

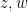


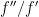







one has



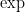



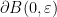
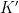
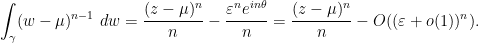

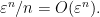
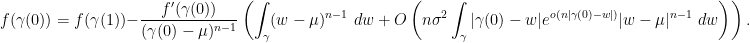
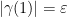
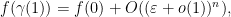







![{K \times [0, 1]}](https://s0.wp.com/latex.php?latex=%7BK+%5Ctimes+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




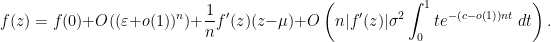

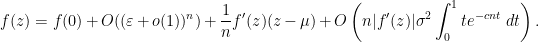


of
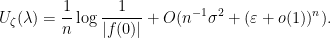
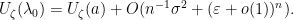
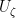

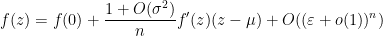
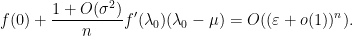






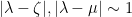


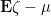


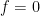


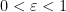
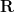







be standard. Then

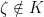







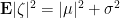




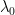
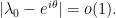
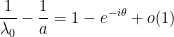

![{\theta_+ \in [0.98\pi, 0.99\pi],\theta_- \in [1.01\pi, 1.02\pi]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta_%2B+%5Cin+%5B0.98%5Cpi%2C+0.99%5Cpi%5D%2C%5Ctheta_-+%5Cin+%5B1.01%5Cpi%2C+1.02%5Cpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
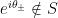


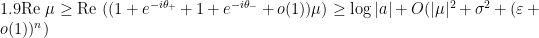
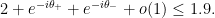







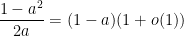


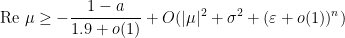
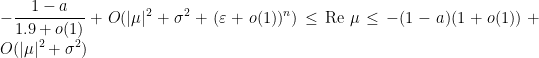

![{1 + \frac{1}{1.9 + o(1)} + o(1) \in [1, 2]}](https://s0.wp.com/latex.php?latex=%7B1+%2B+%5Cfrac%7B1%7D%7B1.9+%2B+o%281%29%7D+%2B+o%281%29+%5Cin+%5B1%2C+2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)






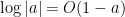


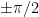
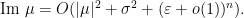



be a standard compact set. Then for every
,

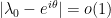
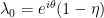




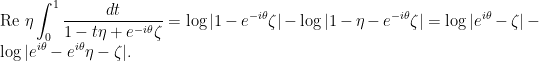






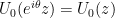



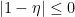
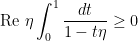



be a holomorphic function with zeroes
and
. Then



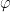
,

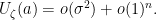

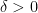

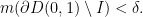

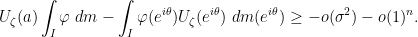
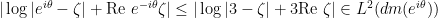


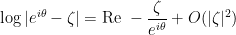











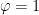






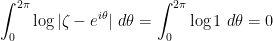

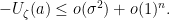






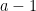 is infinitesimal, and
is infinitesimal, and .
.




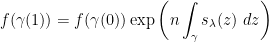
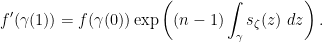
 are identically distributed and almost surely lie in
are identically distributed and almost surely lie in
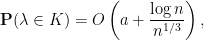
 is infinitesimal in probability.
is infinitesimal in probability.
 is infinitesimal (case zero), or
is infinitesimal (case zero), or such that
such that

 .
.  are identically distributed and almost surely are
are identically distributed and almost surely are 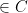 .
. such that for every
such that for every ![{|z| \in [r_1, r_2]}](https://s0.wp.com/latex.php?latex=%7B%7Cz%7C+%5Cin+%5Br_1%2C+r_2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, 
 is holomorphic away from
is holomorphic away from 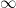 then
then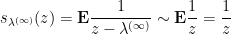
 is discrete, so there are
is discrete, so there are 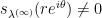 whenever
whenever ![{r \in [r_1, r_2]}](https://s0.wp.com/latex.php?latex=%7Br+%5Cin+%5Br_1%2C+r_2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . To see this, suppose not; then for every
. To see this, suppose not; then for every  we can find
we can find  , so
, so  . Since this is definitely not true, the claim follows by continuity of
. Since this is definitely not true, the claim follows by continuity of  , so
, so 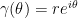 where
where  ; then
; then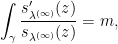
 , which contradicts that
, which contradicts that 

 on an annulus. Indeed, convergence in
on an annulus. Indeed, convergence in  is a smooth cutoff supported on
is a smooth cutoff supported on  (where
(where  ), one has
), one has
 term is easy to deal with, since for every
term is easy to deal with, since for every 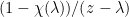 is a bounded continuous function of
is a bounded continuous function of  (so
(so  ). By the definition of being infinitesimal in distribution we have
). By the definition of being infinitesimal in distribution we have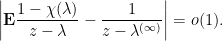
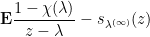
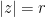 then
then 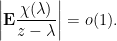
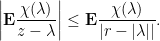
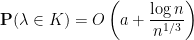
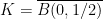 . Since
. Since  and
and  it follows that
it follows that
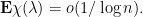
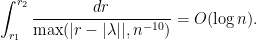
![\displaystyle \int_{\substack{[r_1,r_2]\\|r-|\lambda|| \leq n^{-10}}} \frac{dr}{\max(|r - |\lambda||, n^{-10})} \leq 2n^{-10}n^{10} = 2 = O(\log n)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7B%5Csubstack%7B%5Br_1%2Cr_2%5D%5C%5C%7Cr-%7C%5Clambda%7C%7C+%5Cleq+n%5E%7B-10%7D%7D%7D+%5Cfrac%7Bdr%7D%7B%5Cmax%28%7Cr+-+%7C%5Clambda%7C%7C%2C+n%5E%7B-10%7D%29%7D+%5Cleq+2n%5E%7B-10%7Dn%5E%7B10%7D+%3D+2+%3D+O%28%5Clog+n%29&bg=ffffff&fg=000000&s=0&c=20201002)
 . On the other hand, the other term
. On the other hand, the other term![\displaystyle \int_{\substack{[r_1,r_2]\\|r-|\lambda|| \geq n^{-10}}} \frac{dr}{\max(|r - |\lambda||, n^{-10})} \leq \int_{n^{-10}}^{r_2 - r_1} \frac{dr}{r} = \log(r_2 - r_1) - 10 \log n = O(\log n)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7B%5Csubstack%7B%5Br_1%2Cr_2%5D%5C%5C%7Cr-%7C%5Clambda%7C%7C+%5Cgeq+n%5E%7B-10%7D%7D%7D+%5Cfrac%7Bdr%7D%7B%5Cmax%28%7Cr+-+%7C%5Clambda%7C%7C%2C+n%5E%7B-10%7D%29%7D+%5Cleq+%5Cint_%7Bn%5E%7B-10%7D%7D%5E%7Br_2+-+r_1%7D+%5Cfrac%7Bdr%7D%7Br%7D+%3D+%5Clog%28r_2+-+r_1%29+-+10+%5Clog+n+%3D+O%28%5Clog+n%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is standard while
is standard while 
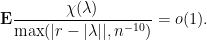
 then there is a (deterministic) zero
then there is a (deterministic) zero  , thus
, thus  lies in a set of measure
lies in a set of measure  such sets since there are
such sets since there are 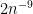 , which is infinitesimal. Therefore
, which is infinitesimal. Therefore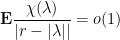
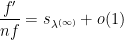
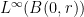 , where
, where 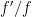 ; that is, the number of critical points minus zeroes of
; that is, the number of critical points minus zeroes of  does commute with the argument principle, so we can throw out the infinitesimal
does commute with the argument principle, so we can throw out the infinitesimal 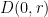 . So
. So 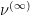 of
of 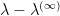 is infinitesimal in distribution,
is infinitesimal in distribution, 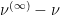 is infinitesimal in the weak topology of measures; that is, for every continuous function
is infinitesimal in the weak topology of measures; that is, for every continuous function 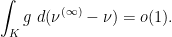
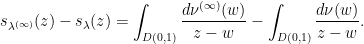
 is Lebesgue measure then
is Lebesgue measure then

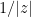 is Lebesgue integrable in codimension
is Lebesgue integrable in codimension 
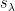 .
.
 , but does have
, but does have  . Similar pseudo-counterexamples hold for
. Similar pseudo-counterexamples hold for ; here
; here  is an infinitesimal raised to the power of
is an infinitesimal raised to the power of 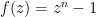 .
. , one has
, one has 
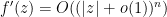

 , and consists of isolated points of
, and consists of isolated points of  is infinitesimal in
is infinitesimal in 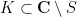 :
: 
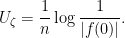



 ,
,

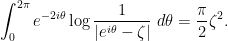


![{|a - \zeta| \in [1, 2]}](https://s0.wp.com/latex.php?latex=%7B%7Ca+-+%5Czeta%7C+%5Cin+%5B1%2C+2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , one has
, one has
![{s \in [1, 2]}](https://s0.wp.com/latex.php?latex=%7Bs+%5Cin+%5B1%2C+2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) one has
one has  (which follows by Taylor expansion). In particular,
(which follows by Taylor expansion). In particular,
 be the best approximation of
be the best approximation of 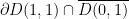 , which exists since that arc is compact; then
, which exists since that arc is compact; then
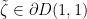 , it has the useful property that
, it has the useful property that![\displaystyle \text{arg }\zeta \in [\pi/3,\pi/2] \cup [-\pi/2, -\pi/3];](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7Barg+%7D%5Czeta+%5Cin+%5B%5Cpi%2F3%2C%5Cpi%2F2%5D+%5Ccup+%5B-%5Cpi%2F2%2C+-%5Cpi%2F3%5D%3B&bg=ffffff&fg=000000&s=0&c=20201002)


 several times. First we bound
several times. First we bound
 before applying the inequality. Now we bound
before applying the inequality. Now we bound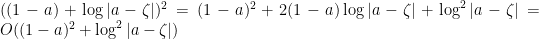
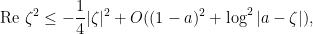
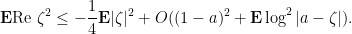



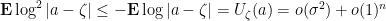
![{\log |a - \zeta| \in [0, 1]}](https://s0.wp.com/latex.php?latex=%7B%5Clog+%7Ca+-+%5Czeta%7C+%5Cin+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.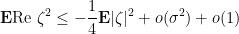

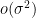 term as
term as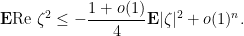


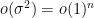
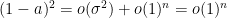

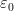 was standard, which implies
was standard, which implies  be a polynomial of degree
be a polynomial of degree  that has all zeroes
that has all zeroes  . If
. If 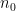 on the degree of a counterexample and then use a computer-assisted proof to complete the argument. I think that for every
on the degree of a counterexample and then use a computer-assisted proof to complete the argument. I think that for every 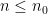 you’d get a formula in the theory of real closed fields that could be decided in
you’d get a formula in the theory of real closed fields that could be decided in  time, where
time, where  . If for every
. If for every  , where
, where  does not depend on
does not depend on  , then there is an infinitesimal
, then there is an infinitesimal 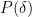 .
.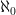 -saturation) If
-saturation) If 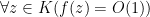 where
where  is exactly the space of ultrafilters on
is exactly the space of ultrafilters on  of
of  , which then is a nonprincipal ultrafilter. If
, which then is a nonprincipal ultrafilter. If  denotes the ultrapower of
denotes the ultrapower of  in
in  has been fixed, we have a canonical way to pass to subsequences: only pass to a subsequence which converges to
has been fixed, we have a canonical way to pass to subsequences: only pass to a subsequence which converges to 
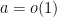 and in the latter we have
and in the latter we have 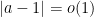 . We’ll call the former “case zero” and the latter “case one.”
. We’ll call the former “case zero” and the latter “case one.” , by using our chosen ultrafilter to repeatedly pass to subsequences to make
, by using our chosen ultrafilter to repeatedly pass to subsequences to make  almost surely (resp.
almost surely (resp. 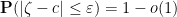 ), and this makes sense even though the probability space we are studying depends on
), and this makes sense even though the probability space we are studying depends on  that deos not depend on
that deos not depend on 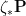 converge vaguely to
converge vaguely to  .
. is infinitesimally close to a standard measure
is infinitesimally close to a standard measure 
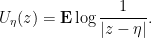
 denotes expected value. Tao claims but does not prove that this definition makes sense for almost every
denotes expected value. Tao claims but does not prove that this definition makes sense for almost every  . To check this, let
. To check this, let 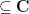 equipped with Lebesgue measure
equipped with Lebesgue measure 
 , which has real codimension
, which has real codimension 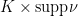 . The double integral of a logarithm makes sense almost surely provided that the logarithm blows up with real codimension
. The double integral of a logarithm makes sense almost surely provided that the logarithm blows up with real codimension 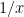 on
on 
 is “less singular” than
is “less singular” than  denote the distribution of
denote the distribution of 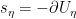 and
and  where
where  are the complex derivative and Cauchy-Riemann operators respectively. Since
are the complex derivative and Cauchy-Riemann operators respectively. Since  we have
we have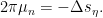
 almost surely? In that case
almost surely? In that case  . Everything looks good, since
. Everything looks good, since 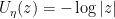 .
.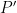 belong to the convex hull of the variety
belong to the convex hull of the variety  .
.  .
. 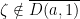 .
.  . For almost every
. For almost every 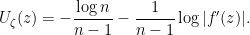
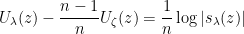

 is the coefficient of
is the coefficient of  in
in  . The roots of
. The roots of 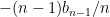 by calculus. So
by calculus. So 

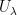 and
and  follows by subtracting the above formulae, as does the formula for
follows by subtracting the above formulae, as does the formula for  .
. 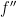 by the above lemma and the following proposition.
by the above lemma and the following proposition.![{C = \{e^{i\theta}: 2\theta \in [\pi, 3\pi]\}}](https://s0.wp.com/latex.php?latex=%7BC+%3D+%5C%7Be%5E%7Bi%5Ctheta%7D%3A+2%5Ctheta+%5Cin+%5B%5Cpi%2C+3%5Cpi%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , so
, so 
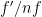 , so by a stability-of-zeroes argument to show that
, so by a stability-of-zeroes argument to show that  , which we can then use to deduce a contradiction.
, which we can then use to deduce a contradiction. if
if  is the Laplacian of
is the Laplacian of