Recently, both through grading proofs and trying to teach some new math majors how to write proofs, I’ve had the opportunity to see a lot of invalid proofs. I want to record here some of the more common errors that invalidate an argument here.
Compilation errors. When grading a huge stack of problem sets, I kind of feel like a compiler. I go through each argument and stop once I run into an error. If I can guess what the author meant to say, I throw a warning (i.e. take off points) but continue reading; otherwise, I crash (i.e. mark the proof wrong).
So by a compilation error, I just mean an error in which the student had an argument which is probably valid in their heads, but when they wrote it down, they mixed up quantifiers, used an undefined term, wrote something syntactically invalid, or similar. I believe that these are the most common errors. Here are some examples of sentences in proofs that I would consider as committing a compilation error:
For a conic section  ,
, 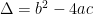 .
.
Here the variable  are undefined at the time that they are used, while the variable is never used after it is bound. From context, I can guess that
are undefined at the time that they are used, while the variable is never used after it is bound. From context, I can guess that 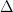 is supposed to be the discriminant of , and is supposed to be the conic section in the
is supposed to be the discriminant of , and is supposed to be the conic section in the  -plane cut out by the equation
-plane cut out by the equation 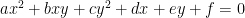 where
where 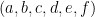 are constants. So this isn’t too egregious but it is still an error, and in more complicated arguments could potentially be a serious issue.
are constants. So this isn’t too egregious but it is still an error, and in more complicated arguments could potentially be a serious issue.
There’s another thing problematic about this example. We use “For” without a modifier “For every” or “For some”. Does just one conic section satisfy the equation , or does every conic section satisfy this equation? Of course, the author meant that every conic section satisfies this equation, and in fact probably meant this equation to be a definition of . So this compilation error can be fixed by instead writing:
Let be the conic section in the -plane defined by the equation . Then let be the discriminant of .
Here’s another compilation error:
Let  be a
be a  -dimensional vector space. For every
-dimensional vector space. For every 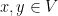 , define
, define  .
.
Here the author probably means that 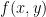 is the cross-product, or the wedge product, or the polynomial product, or the tensor product, or some other kind of product, of
is the cross-product, or the wedge product, or the polynomial product, or the tensor product, or some other kind of product, of 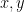 . But we don’t know which product it is! Indeed, is just some three-dimensional vector space, so it doesn’t come with a product structure. We could fix this by writing, for example:
. But we don’t know which product it is! Indeed, is just some three-dimensional vector space, so it doesn’t come with a product structure. We could fix this by writing, for example:
Let  , and for every , define
, and for every , define  for the cross product of .
for the cross product of .
We have seen that compilation errors are usually just caused by sloppiness. That doesn’t mean that compilation errors can’t point to a more serious problem with one’s proof — they could, for example, obscure a key step in the argument which is actually fatally flawed. Arguably, this is the case with Shinichi Mochizuki’s infamous incorrect proof of Szpiro’s Conjecture. However, I think that most beginners can avoid compilation errors by making sure that they define every variable before using it, are never ambiguous about if they mean “for every” or “for some”, and otherwise just being very careful in their writing. And beginners should avoid using symbol-soup whenever possible, in favor of the English language. If you ever write something like
Suppose that  .
.
I will probably take off points, even though I can, in principle, parse what you’re trying to say. The reason is that you could just as well write
Suppose that  is a function, and for every
is a function, and for every 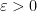 we can find a
we can find a  such that for any
such that for any  such that
such that  ,
,  .
.
which is much easier to read.
Edge-case errors. An edge-case error is an error in a proof, where the proof manages to cover every case except for a single special case where the proof fails. These errors are also often caused by sloppiness, but are more likely to actually be a serious flaw in an argument than a compilation error. They also tend to be a lot harder to detect than compilation errors. Here’s an example:
Let 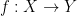 be a function. Then there is some
be a function. Then there is some  in the image of
in the image of  .
.
Do you see the problem? Don’t read ahead until you try to find it for a few minutes.
Okay, first of all, if you read ahead without trying to find the problem, shame on you; second of all, if you’ve written something like this, don’t feel shame, because it’s a common mistake. The issue, of course, is that  is allowed to be the empty set, in which case is the infamous empty function into
is allowed to be the empty set, in which case is the infamous empty function into  .
.
Most of the time the empty function isn’t too big of an issue, but it can come up sometimes. For example, the fact that the empty function exists means that arguably 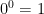 , which is problematic because it means that the function
, which is problematic because it means that the function 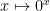 is not continuous (since if
is not continuous (since if  then
then 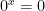 ).
).
Here’s an example from topology:
Let be a connected space and let  . Then let
. Then let 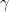 be a path from
be a path from 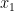 to
to 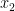 .
.
In practice, most spaces we care about are quite nice — manifolds, varieties, CW-complexes, whatever. In such spaces, if they are connected we can find a path between any two points. However, this is not true in general, and the famous counterexample is the topologist’s sine curve. The point is that it’s very important to make sure you get your assumptions right — if you wrote this in a proof there’s a good chance it would cause the rest of the argument to fail, unless you had an additional assumption that the space did in fact have the property that connected implied path-connected.
In general, a good strategy to avoid errors like the above error is to beware of the standard counterexamples of whatever area of math you are currently working in, and make sure none of them can sneak past your argument! One way to think about this is to imagine that you are Alice, and Bob is handing you the best counterexamples he can find for your argument. You can only beat Bob if you can demonstrate that none of his counterexamples actually work.
Let me also give an example from my own work.
Let be a bounded subset of 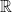 . Then the supremum of exists and is an element of .
. Then the supremum of exists and is an element of .
It sure looks like this statement is true, since is a complete order. But in fact, could be the empty set, in which case every real number is an upper bound on and so 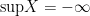 . In most cases, the reaction would be “So what? It’s just an edge case error.” But actually, in my case, I later discovered that the thing I was trying to prove was only interesting in the case that was the empty set, in which case this step of the argument immediately fails. A month later, I’m still not sure what to do to get around this issue, though I have some ideas.
. In most cases, the reaction would be “So what? It’s just an edge case error.” But actually, in my case, I later discovered that the thing I was trying to prove was only interesting in the case that was the empty set, in which case this step of the argument immediately fails. A month later, I’m still not sure what to do to get around this issue, though I have some ideas.
Fatal errors. These are errors which immediately cause the entire argument to fail. If they can be patched, so much the better, but unlike the other two types of errors that can usually be worked around, a fatal error often cannot be repaired.
The most common fatal error I see in beginners’ proofs is the circular argument, as in the below example:
We claim that every vector space is finite-dimensional. In fact, if 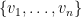 is a basis of the vector space , then
is a basis of the vector space , then  , which proves our claim.
, which proves our claim.
If you read a standard textbook on linear algebra, they will certainly assume that given a vector space , you can find a basis of . But in fact, such a finite basis only exists if, a priori, is finite-dimensional! So all the student here has managed to prove is that if is a finite-dimensional vector space, then is a finite-dimensional vector space… not very interesting.
(This is not to say that there are almost-circular arguments which do prove something nontrivial. Induction is a form of this, as is the closely related “proof by a priori estimate” technique used in differential equations. But if one looks closely at these arguments they will see that they are not, in fact, circular.)
The other kind of fatal error is similar: there’s some sneaky assumption used in the proof, which isn’t really an edge case assumption. I have blogged about an insidious such assumption, namely the continuum hypothesis. In general, these assumptions often are related to edge-case issues, but may even happen in the generic case, as you mentally make an assumption that you forget to keep track of. Here is another example, also from measure theory:
Let be a Banach space and let ![F: [0, 1] \to X](https://s0.wp.com/latex.php?latex=F%3A+%5B0%2C+1%5D+%5Cto+X&bg=ffffff&fg=000000&s=0&c=20201002) be a bounded measurable function. Then we can find a sequence
be a bounded measurable function. Then we can find a sequence  of simple measurable functions such that
of simple measurable functions such that 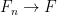 almost everywhere pointwise and is Cauchy in mean, so we define
almost everywhere pointwise and is Cauchy in mean, so we define  .
.
This definition looks like the standard definition of an integral in any measure theory course. However, without a stronger assumption on , it’s just nonsense. For one thing, we haven’t shown that the definition of  doesn’t depend on the choice of . That can be fixed. What cannot be fixed is that might not exist at all! This happens if is not separable, in which case the definition of the integral is nonsense.
doesn’t depend on the choice of . That can be fixed. What cannot be fixed is that might not exist at all! This happens if is not separable, in which case the definition of the integral is nonsense.
This sort of fatal error is particularly tricky to deal with when one is first learning a more general version of a familiar theory. Most undergraduates are familiar with linear algebra, and the fact that every finite-dimensional vector space has a basis. In particular, every element of a vector space can be written uniquely in terms of a given basis. So when one first learns about finite abelian groups, they might be tempted to write:
Let  be a finite abelian group, and let
be a finite abelian group, and let 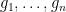 be a minimal set of generators of . Then for every
be a minimal set of generators of . Then for every 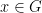 there are unique
there are unique 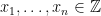 such that
such that  .
.
In fact, the counterexample here is 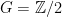 ,
, 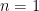 ,
, 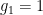 , and
, and  , because we can write
, because we can write 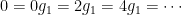 . So, when generalizing a theory, one does need to be really careful that they haven’t “imported” a false theorem to higher generality! (There’s no shame in making this mistake, though; I think that many mathematicians tried to prove Fermat’s Last Theorem but committed this error by assuming that unique factorization would hold in certain rings — after all, unique factorization holds in everyone’s favorite ring
. So, when generalizing a theory, one does need to be really careful that they haven’t “imported” a false theorem to higher generality! (There’s no shame in making this mistake, though; I think that many mathematicians tried to prove Fermat’s Last Theorem but committed this error by assuming that unique factorization would hold in certain rings — after all, unique factorization holds in everyone’s favorite ring 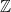 — that it fails in.)
— that it fails in.)
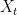





be an asymmetric norm on
, let
.
.












































,
.




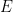
.
such that for every
, with
,
.










such that for each point
.






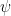









![q \in [-R, R]^n](https://s0.wp.com/latex.php?latex=q+%5Cin+%5B-R%2C+R%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002)
![2^{-r} \mathbf Z^n \cap [-R, R]^n](https://s0.wp.com/latex.php?latex=2%5E%7B-r%7D+%5Cmathbf+Z%5En+%5Ccap+%5B-R%2C+R%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002)




.
in lexicographic order:
.
, return
.














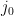










 . We say that two smooth foliations F, G of codimension 1 in
. We say that two smooth foliations F, G of codimension 1 in 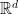 are orthogonal if for any
are orthogonal if for any  , the leaves X, Y of F, G passing through p are orthogonal at p.
, the leaves X, Y of F, G passing through p are orthogonal at p.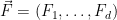 be a d-tuple of mutually orthogonal foliations of codimension 1 in
be a d-tuple of mutually orthogonal foliations of codimension 1 in  denote the leaf of
denote the leaf of 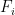 passing through p, and let
passing through p, and let . Then
. Then 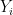 is tangent to a principal curvature vector of
is tangent to a principal curvature vector of  at p whenever
at p whenever 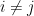 .
.
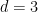 , but it was brought to my attention by
, but it was brought to my attention by  . This appears to be for superficial reasons: the usual proof is based on properties of the cross product which clearly only hold when
. This appears to be for superficial reasons: the usual proof is based on properties of the cross product which clearly only hold when  as well, but Dupin’s theorem is vacuously true in that case.)
as well, but Dupin’s theorem is vacuously true in that case.) smooth hypersurfaces, each of which are mutually orthogonal and therefore are transverse. So
smooth hypersurfaces, each of which are mutually orthogonal and therefore are transverse. So  such that the level sets of
such that the level sets of 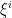 are the leaves of
are the leaves of  . Orthogonality of
. Orthogonality of 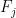 means that
means that  . Therefore the cometric
. Therefore the cometric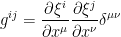
 .
.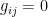 , we obtain
, we obtain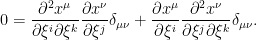

 ,
, 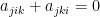 ,
,  ,
,  ,
,  ,
,  . Here, the first three equations arise from the formula for the differentiated metric and the last three originate from symmetry of second partial derivatives. The only solution of this system of this equation is
. Here, the first three equations arise from the formula for the differentiated metric and the last three originate from symmetry of second partial derivatives. The only solution of this system of this equation is  for every distinct triple (i, j, k), or in other words
for every distinct triple (i, j, k), or in other words  .
.
 . Therefore every vector in L is contained in a vector space of dimension
. Therefore every vector in L is contained in a vector space of dimension 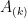 be the second fundamental form of
be the second fundamental form of  , written in the coordinate system
, written in the coordinate system .
. is equal to a scalar times the Hodge star of the wedge product of all of the vectors in L. Since the wedge product of L vanishes, so does
is equal to a scalar times the Hodge star of the wedge product of all of the vectors in L. Since the wedge product of L vanishes, so does 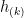 on
on  ,
,  .
. is a principal curvature vector of
is a principal curvature vector of  . But
. But  be a partial differential equation, which for simplicity I will take to be a linear, elliptic equation of second order with homogeneous Dirichlet data on a compact polytope
be a partial differential equation, which for simplicity I will take to be a linear, elliptic equation of second order with homogeneous Dirichlet data on a compact polytope 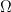 . The canonical example is that P is the
. The canonical example is that P is the 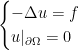
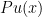 from the
from the 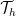 of partitions of
of partitions of 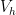 of PL shape functions, which are continuous functions on
of PL shape functions, which are continuous functions on 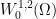 . Of course, other Sobolev spaces admit better choices of shape functions, which in some cases can be easily read off of the
. Of course, other Sobolev spaces admit better choices of shape functions, which in some cases can be easily read off of the 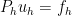 . If we can solve this equation, then by the orthogonality of the projection, the
. If we can solve this equation, then by the orthogonality of the projection, the 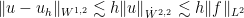
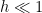 we have a good solution in
we have a good solution in 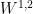 . By modifying the choice of Sobolev spaces and shape functions we can obtain bounds at other regularities.
. By modifying the choice of Sobolev spaces and shape functions we can obtain bounds at other regularities. in a practical amount of time, however:
in a practical amount of time, however: .
. of
of  .
.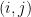 is a pair of indices corresponding to a shape function on a simplex K, then the only nonzero entries in row i or column j are for shape functions on simplices which are adjacent to K.
is a pair of indices corresponding to a shape function on a simplex K, then the only nonzero entries in row i or column j are for shape functions on simplices which are adjacent to K.
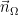 is the normal field to
is the normal field to 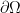 , and the electric current J is given. The right-hand side of the equation
, and the electric current J is given. The right-hand side of the equation 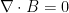 is not data, so that zero is not secretly an epsilon: it asserts that B has no
is not data, so that zero is not secretly an epsilon: it asserts that B has no 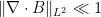 or a similar “approximate monopole inequality”. I will refer to such a B as divergence conforming; a similar condition appears when one tries to solve the Stokes or Navier-Stokes equations for a liquid.
or a similar “approximate monopole inequality”. I will refer to such a B as divergence conforming; a similar condition appears when one tries to solve the Stokes or Navier-Stokes equations for a liquid.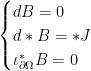
 is the inclusion map. This interpretation is quite natural, because it views B as something that we want to integrate over a surface
is the inclusion map. This interpretation is quite natural, because it views B as something that we want to integrate over a surface 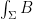 is now the
is now the 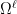 be the space of
be the space of 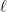 -forms,
-forms,  the kernel of
the kernel of 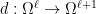 , and observe that
, and observe that
 is a finite-dimensional space that does not depend on h, so we can solve it separately. So we may assume that
is a finite-dimensional space that does not depend on h, so we can solve it separately. So we may assume that 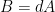 for some 1-form A. Without loss of generality, we may assume that A is in
for some 1-form A. Without loss of generality, we may assume that A is in 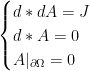
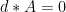 , so if we pick up some numerical error there, it doesn’t matter. After all, we actually care about
, so if we pick up some numerical error there, it doesn’t matter. After all, we actually care about  , not A itself, and
, not A itself, and 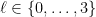 . We cannot choose them arbitrarily, however, because we must preserve unisolvence of the maps
. We cannot choose them arbitrarily, however, because we must preserve unisolvence of the maps 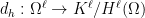 . The natural norm to put on
. The natural norm to put on 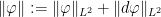
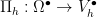 where
where 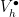 is a family of chain complexes associated to the triangulations
is a family of chain complexes associated to the triangulations 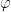 on
on 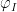 is a linear function on
is a linear function on 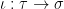 is a k-face of
is a k-face of 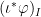 is a constant function on
is a constant function on  for every increasing multiindex I.
for every increasing multiindex I.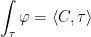 .
.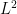 k-forms
k-forms  ,
,  is a Whitney k-form on
is a Whitney k-form on  in
in  exists in the sense of the Sobolev trace theorem. In particular, there is no jump discontinuity.
exists in the sense of the Sobolev trace theorem. In particular, there is no jump discontinuity. associated to a triangulation
associated to a triangulation  in the Whitney complex associated to
in the Whitney complex associated to  .
. .
.

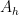 , and then
, and then  satisfies
satisfies
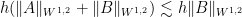
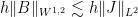

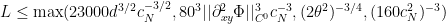
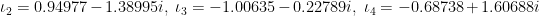 .
.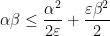

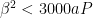
 suitably. Messing around with Cauchy’s product inequality (I did this in desmos), you can convince yourself that the constant in (2.32) can be a little bit bigger than 0.001, but Zhang decided to round down to make the statement of (2.32) less messy.
suitably. Messing around with Cauchy’s product inequality (I did this in desmos), you can convince yourself that the constant in (2.32) can be a little bit bigger than 0.001, but Zhang decided to round down to make the statement of (2.32) less messy.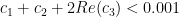 .
.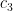 probably easily follows from the iotas, which suggests that he probably made those choices so that
probably easily follows from the iotas, which suggests that he probably made those choices so that 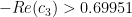 would be just barely smaller than
would be just barely smaller than 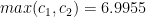 . Those constants are calculated in Sections 8 and 9 respectively. Anyways, since Sections 8 and 9 depend on the iotas as well, it would not be unreasonable to speculate that using some numerical analysis he was able to find that as long as the constants lived in some small ball in the complex plane they would be OK, and then rounded to sufficient precision to obtain the choice of iotas.
. Those constants are calculated in Sections 8 and 9 respectively. Anyways, since Sections 8 and 9 depend on the iotas as well, it would not be unreasonable to speculate that using some numerical analysis he was able to find that as long as the constants lived in some small ball in the complex plane they would be OK, and then rounded to sufficient precision to obtain the choice of iotas.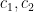 is probably the hard part of the proof, so I’m not going to try to understand it. However, skimming Sections 8 and 9, it seems like
is probably the hard part of the proof, so I’m not going to try to understand it. However, skimming Sections 8 and 9, it seems like 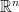 .
.
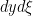 is the measure induced by the symplectic structure on the cotangent bundle and a is the symbol. We also call P a quantization of a.
is the measure induced by the symplectic structure on the cotangent bundle and a is the symbol. We also call P a quantization of a.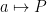 is not quite a morphism of algebras (essentially since symbols commute but pseudodifferential operators do not), we can “approximately invert” P by quantizing 1/a.
is not quite a morphism of algebras (essentially since symbols commute but pseudodifferential operators do not), we can “approximately invert” P by quantizing 1/a.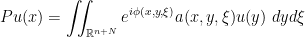
 is positively homogeneous of degree 1 on each fiber of
is positively homogeneous of degree 1 on each fiber of 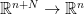 , is smooth away from the zero section, for every x there is no critical point of
, is smooth away from the zero section, for every x there is no critical point of  away from the zero section, and similarly for y.
away from the zero section, and similarly for y.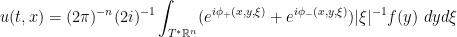
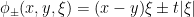 . Thus the solution map is a sum of Fourier integral operators.
. Thus the solution map is a sum of Fourier integral operators.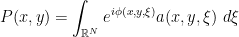
 and so we might as well study the following class of distributions:
and so we might as well study the following class of distributions: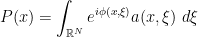
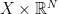 and define the critical set
and define the critical set .
. of
of 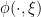 restricts to a map
restricts to a map 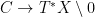 by
by 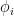 ,
, 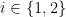 , be phases defined in neighborhoods of
, be phases defined in neighborhoods of  which induce a Lagrangian submanifold
which induce a Lagrangian submanifold  of
of  . Then:
. Then: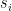 be the signature of the Hessian tensor
be the signature of the Hessian tensor  . Then
. Then 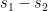 is a locally constant, integer-valued function.
is a locally constant, integer-valued function.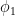 and symbol
and symbol 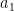 , then there exists a symbol
, then there exists a symbol 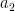 such that A is also an oscillatory integral with phase
such that A is also an oscillatory integral with phase 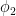 and symbol
and symbol 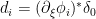
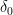 is the Dirac measure on
is the Dirac measure on 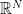 . Then modulo lower-order symbols, we have
. Then modulo lower-order symbols, we have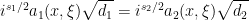 (1)
(1)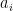 to be supported in an arbitrarily small neighborhood of
to be supported in an arbitrarily small neighborhood of 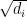 is the formal square root of a measure, it can be viewed intrinsically as a half-density — that is, the formal square root of an unsigned volume form. This is very advantageous to us, because ultimately we want to be able to pair the oscillatory integrals we construct with elements of
is the formal square root of a measure, it can be viewed intrinsically as a half-density — that is, the formal square root of an unsigned volume form. This is very advantageous to us, because ultimately we want to be able to pair the oscillatory integrals we construct with elements of 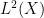 (at least for symbols of order -m where m is large enough), but elements of
(at least for symbols of order -m where m is large enough), but elements of 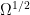 be the half-density sheaf of a Lagrangian submanifold
be the half-density sheaf of a Lagrangian submanifold 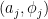 defining an oscillatory integral in an open set
defining an oscillatory integral in an open set 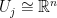 in
in 
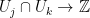 . Chasing the definition of a Čech cochain around, it follows that
. Chasing the definition of a Čech cochain around, it follows that 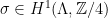 . We recall that since
. We recall that since 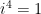 ,
, 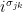 is well-defined (since
is well-defined (since 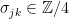 ).
).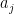 defined on
defined on 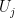 , we have
, we have  .
.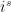 into a, then a is honestly a section of L, and if we absorb a factor of
into a, then a is honestly a section of L, and if we absorb a factor of 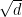 , then a is a section of
, then a is a section of  . Moreover, L is defined independently of anything except
. Moreover, L is defined independently of anything except 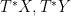 are denoted by
are denoted by  . A canonical relation
. A canonical relation 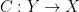 is a closed conic Lagrangian submanifold of
is a closed conic Lagrangian submanifold of 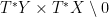 with respect to the symplectic form
with respect to the symplectic form  .
. such that the Schwartz kernel of A is an oscillatory integral whose Lagrangian submanifold is C.
such that the Schwartz kernel of A is an oscillatory integral whose Lagrangian submanifold is C.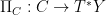 is an immersion.
is an immersion.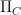 is an immersion; obviously it is a submersion, so the only reason that
is an immersion; obviously it is a submersion, so the only reason that  on C, which induces a natural isomorphism
on C, which induces a natural isomorphism 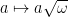 between functions and half-densities. Thus the symbol calculus greatly simplifies, as we can define a symbol in this case to just be a section of the Maslov sheaf. What’s annoying is that if C is a local canonical graph, then X and Y have the same dimension, making it hard to study Fourier integral operators between operators of different dimension.
between functions and half-densities. Thus the symbol calculus greatly simplifies, as we can define a symbol in this case to just be a section of the Maslov sheaf. What’s annoying is that if C is a local canonical graph, then X and Y have the same dimension, making it hard to study Fourier integral operators between operators of different dimension.![\gamma: [0, 1] \to M](https://s0.wp.com/latex.php?latex=%5Cgamma%3A+%5B0%2C+1%5D+%5Cto+M&bg=ffffff&fg=000000&s=0&c=20201002) in a surface M such that we can find local coordinates (x, y) for M around some point on the curve, such that in those coordinates we can view
in a surface M such that we can find local coordinates (x, y) for M around some point on the curve, such that in those coordinates we can view  away from a set of Lebesgue measure zero.
away from a set of Lebesgue measure zero.![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . To construct the Cantor set C, we start with a line segment, and split it into equal thirds. We then discard the middle third, leaving us with two equal-length line segments. We iterate this process infinitely many times. Clearly we can identify the points that we’re left with with the paths through a full infinite binary tree, so the Cantor set is uncountable[1].
. To construct the Cantor set C, we start with a line segment, and split it into equal thirds. We then discard the middle third, leaving us with two equal-length line segments. We iterate this process infinitely many times. Clearly we can identify the points that we’re left with with the paths through a full infinite binary tree, so the Cantor set is uncountable[1]. using the Cantor measure. If
using the Cantor measure. If 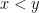 are real numbers, then the Cantor function F is defined by declaring that
are real numbers, then the Cantor function F is defined by declaring that 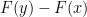 is the probability that
is the probability that  . The standard Devil’s staircase is the graph of the Cantor function.
. The standard Devil’s staircase is the graph of the Cantor function. and there are
and there are  such intervals; it follows that the Cantor set has length at most
such intervals; it follows that the Cantor set has length at most 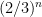 . Since n was arbitrary, the Cantor set has Lebesgue measure zero. Outside the Cantor set, we can explicitly compute
. Since n was arbitrary, the Cantor set has Lebesgue measure zero. Outside the Cantor set, we can explicitly compute 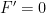 . Since F is a cdf, it is a continuous surjective map
. Since F is a cdf, it is a continuous surjective map ![F: [0, 1] \to [0, 1]](https://s0.wp.com/latex.php?latex=F%3A+%5B0%2C+1%5D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![[0, 1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002) , we define
, we define ![\int_{[0, 1]^2} X ~d\omega = \int_{\{u \leq 0\}} \nabla \cdot X](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C+1%5D%5E2%7D+X+%7Ed%5Comega+%3D+%5Cint_%7B%5C%7Bu+%5Cleq+0%5C%7D%7D+%5Cnabla+%5Ccdot+X&bg=ffffff&fg=000000&s=0&c=20201002) . Then
. Then ![X \mapsto \int_{[0, 1]^2} X ~d\omega](https://s0.wp.com/latex.php?latex=X+%5Cmapsto+%5Cint_%7B%5B0%2C+1%5D%5E2%7D+X+%7Ed%5Comega&bg=ffffff&fg=000000&s=0&c=20201002) can be shown to be bounded on
can be shown to be bounded on  , so it extends to every continuous vector field on
, so it extends to every continuous vector field on  by the Riesz-Markov representation theorem. On the other hand, the divergence theorem says that if an open set
by the Riesz-Markov representation theorem. On the other hand, the divergence theorem says that if an open set 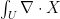 is the integral of the normal part of X to
is the integral of the normal part of X to  . In other words, integrating against
. In other words, integrating against  should represent “integrating the part of the vector field which is normal to the Devil’s staircase”.
should represent “integrating the part of the vector field which is normal to the Devil’s staircase”. of
of  exists for
exists for  must be defined for some x which is not in the horizontal part of the Devil’s staircase. Sharpening
must be defined for some x which is not in the horizontal part of the Devil’s staircase. Sharpening  , we obtain the normal vector field to the Devil’s staircase.
, we obtain the normal vector field to the Devil’s staircase. where
where 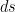 is arc length. So pairing against
is arc length. So pairing against  -dimensional Hausdorff measure of small balls around P. That, in turn, should be computable in terms of the infinite binary string which defines P. But I don’t know how to do that. I’d love to talk about this problem with you, if you do have an idea.
-dimensional Hausdorff measure of small balls around P. That, in turn, should be computable in terms of the infinite binary string which defines P. But I don’t know how to do that. I’d love to talk about this problem with you, if you do have an idea. norms informally: we discuss no duality theory and appeal to no measure theory, but only state the Hoelder and Minkowski inequalities, and take completeness as a black box. We similarly define the
norms informally: we discuss no duality theory and appeal to no measure theory, but only state the Hoelder and Minkowski inequalities, and take completeness as a black box. We similarly define the  norms.
norms.![I[u] = ||\nabla u||_{L^2}^2](https://s0.wp.com/latex.php?latex=I%5Bu%5D+%3D+%7C%7C%5Cnabla+u%7C%7C_%7BL%5E2%7D%5E2&bg=ffffff&fg=000000&s=0&c=20201002) in several different forms: a quantity that is minimized by a chemical system in equilibrium, a term in the Mumford-Shah energy from image processing, and a linear approximation to the Lagrangian action
in several different forms: a quantity that is minimized by a chemical system in equilibrium, a term in the Mumford-Shah energy from image processing, and a linear approximation to the Lagrangian action  for minimal graphs. The case of minimal graphs would be particularly fun to teach, as one can bring in bubble wands and try to predict the shapes of soap films, which locally are minimal graphs. (This activity was suggested in a talk of
for minimal graphs. The case of minimal graphs would be particularly fun to teach, as one can bring in bubble wands and try to predict the shapes of soap films, which locally are minimal graphs. (This activity was suggested in a talk of 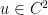 . Then
. Then ![I[u]](https://s0.wp.com/latex.php?latex=I%5Bu%5D&bg=ffffff&fg=000000&s=0&c=20201002) is minimal subject to Dirichlet boundary data iff u solves the Laplace equation.
is minimal subject to Dirichlet boundary data iff u solves the Laplace equation. , which gives the formula for a Newtonian potential almost immediately. The Dirichlet energy also gives an easy proof of uniqueness for the Laplace equation. We then introduce the notion of convolution, motivated by signal-processing filters. Convolution against Gaussians gives an easy proof that harmonic functions are smooth and convolution against the Newtonian potential solves the Laplace equation. (The reason I want to use Gaussians here is that constructing smooth functions of compact support is an annoying technical argument that not all students may be comfortable with.) We conclude by proving the maximum modulus principle, which
, which gives the formula for a Newtonian potential almost immediately. The Dirichlet energy also gives an easy proof of uniqueness for the Laplace equation. We then introduce the notion of convolution, motivated by signal-processing filters. Convolution against Gaussians gives an easy proof that harmonic functions are smooth and convolution against the Newtonian potential solves the Laplace equation. (The reason I want to use Gaussians here is that constructing smooth functions of compact support is an annoying technical argument that not all students may be comfortable with.) We conclude by proving the maximum modulus principle, which  of smooth functions on a torus, and argue that we can approximate them using trigonometric polynomials. Here we take the Stone-Weierstrass theorem as a black box. Taking dual spaces, we introduce the Dirac delta function as the unit of convolution and then define periodic distributions. Since this is a course for undergraduates, it is crucial that this step can be carried out without introducing the notion of a Fréchet space, as one just needs to define covectors on
of smooth functions on a torus, and argue that we can approximate them using trigonometric polynomials. Here we take the Stone-Weierstrass theorem as a black box. Taking dual spaces, we introduce the Dirac delta function as the unit of convolution and then define periodic distributions. Since this is a course for undergraduates, it is crucial that this step can be carried out without introducing the notion of a Fréchet space, as one just needs to define covectors on 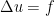 satisfies the estimate
satisfies the estimate 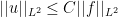 , no such estimate is available for the wave equation, and I can say something vague here about the symbol being a nondegenerate conic section.
, no such estimate is available for the wave equation, and I can say something vague here about the symbol being a nondegenerate conic section.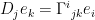 . Here and always we use Einstein’s convention.
. Here and always we use Einstein’s convention.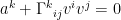 , which to mathematicians is more popularly known as the geodesic equation. It says that the “acceleration” in the coordinate frame e is entirely due to the fact that e itself is an accelerated frame.
, which to mathematicians is more popularly known as the geodesic equation. It says that the “acceleration” in the coordinate frame e is entirely due to the fact that e itself is an accelerated frame. as a bilinear form, we can rewrite Newton’s first law as
as a bilinear form, we can rewrite Newton’s first law as  , which now resembles Newton’s second law with unit mass. Indeed, the acceleration of the particle is given exactly by a quantity
, which now resembles Newton’s second law with unit mass. Indeed, the acceleration of the particle is given exactly by a quantity  which can be reasonably interpreted as a “force”. For example, one could consider the case that the spatial origin is a particle P which is orbiting around a point. If one believes that P really is “inertial”, then they will measure a fictitious force — the centrifugal force — acting on all objects. In general relativity, moreover, I think that the notion of “inertial” is ill-defined. In this case, if v is timelike then $\Gamma^k(v, v)$ is the acceleration due to gravity. In particular these fictitious forces all scale linearly with mass, because the geodesic equation does not have a mass factor and so we need to cancel out the factor of mass in the law
which can be reasonably interpreted as a “force”. For example, one could consider the case that the spatial origin is a particle P which is orbiting around a point. If one believes that P really is “inertial”, then they will measure a fictitious force — the centrifugal force — acting on all objects. In general relativity, moreover, I think that the notion of “inertial” is ill-defined. In this case, if v is timelike then $\Gamma^k(v, v)$ is the acceleration due to gravity. In particular these fictitious forces all scale linearly with mass, because the geodesic equation does not have a mass factor and so we need to cancel out the factor of mass in the law 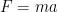 .
. as a quadratic form valued in the tangent space. In other words it is tempting to think of
as a quadratic form valued in the tangent space. In other words it is tempting to think of  as a section of
as a section of 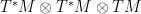 . This of course presupposes that M has a trivial tangent bundle, since the Christoffel symbols are only defined locally. Putting our doubts aside, this is equivalent to thinking of
. This of course presupposes that M has a trivial tangent bundle, since the Christoffel symbols are only defined locally. Putting our doubts aside, this is equivalent to thinking of 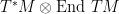 .
.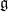 as both subsets of End E, whenever E is a G-bundle. By a gauge transformation of a G-bundle E one means a section of End E which is in fact a section of G. Thus gauge transformations act on E (and so also on End E, etc.)
as both subsets of End E, whenever E is a G-bundle. By a gauge transformation of a G-bundle E one means a section of End E which is in fact a section of G. Thus gauge transformations act on E (and so also on End E, etc.) but in fact are sections of
but in fact are sections of  . (Briefly, the Christoffel symbols are
. (Briefly, the Christoffel symbols are 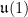 -valued 1-forms — in other words, imaginary 1-forms. A gauge transformation, then, is defined by adding an imaginary exact 1-form to the Christoffel symbols. We interpret the Christoffel symbols A as (i times) potentials for the electromagnetic field. In fact, one can take the exterior derivative of A and obtain a closed 2-form
-valued 1-forms — in other words, imaginary 1-forms. A gauge transformation, then, is defined by adding an imaginary exact 1-form to the Christoffel symbols. We interpret the Christoffel symbols A as (i times) potentials for the electromagnetic field. In fact, one can take the exterior derivative of A and obtain a closed 2-form  , which one can view as the Faraday tensor. The fact that one can add an exact 1-form to A is exactly the gauge invariance of the Maxwell equation
, which one can view as the Faraday tensor. The fact that one can add an exact 1-form to A is exactly the gauge invariance of the Maxwell equation  where j is the current 1-form.
where j is the current 1-form.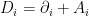 . So for a function u (i.e. a section of the trivial bundle E) on M,
. So for a function u (i.e. a section of the trivial bundle E) on M, 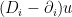 weights u according to the strength of the electromagnetic potential. This is mainly interesting when u is a constant function, in which case
weights u according to the strength of the electromagnetic potential. This is mainly interesting when u is a constant function, in which case 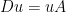 is the potential rescaled by u.
is the potential rescaled by u. or
or 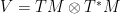 above). In any particular case they should have a nice physical interpretation but I don’t think one can interpret the Maxwell-Yang-Mills case and the Levi-Civita case as one and the same.
above). In any particular case they should have a nice physical interpretation but I don’t think one can interpret the Maxwell-Yang-Mills case and the Levi-Civita case as one and the same.