In this blog post I will just record some things I’ve been trying to learn about lately, largely just so I can have a place to collect my thoughts. Most of this is in Hörmander’s monograph on differential operators, and is motivated by trying to understand Vasy’s method and Atiyah-Singer index theory.
Pseudodifferential operators on manifolds.
Let us recall that a symbol on an open subset X of 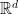 is by definition a smooth function on the cotangent bundle of X (for which certain seminorms are finite). This was curious to me — you can motivate it by saying that a symbol is an observable and the cotangent bundle is “phase space” in the sense that a point
is by definition a smooth function on the cotangent bundle of X (for which certain seminorms are finite). This was curious to me — you can motivate it by saying that a symbol is an observable and the cotangent bundle is “phase space” in the sense that a point  consists of a position x and a momentum
consists of a position x and a momentum 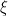 , but why should the momentum live in a cotangent space and not the fiber of some other vector bundle? When we quantize a symbol a, defining an operator a(D) by formally substituting the differential operator
, but why should the momentum live in a cotangent space and not the fiber of some other vector bundle? When we quantize a symbol a, defining an operator a(D) by formally substituting the differential operator  in place of the momentum, we by definition obtain a pseudodifferential operator. Now let
in place of the momentum, we by definition obtain a pseudodifferential operator. Now let  be a diffeomorphism, and introduce the pushforward symbol
be a diffeomorphism, and introduce the pushforward symbol 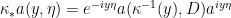 . This is the “right” definition in the sense that
. This is the “right” definition in the sense that  .
.
If a is a symbol of order m, then  modulo symbols of order m – 1. But
modulo symbols of order m – 1. But  is invariantly defined as an isomorphism of tangent bundles
is invariantly defined as an isomorphism of tangent bundles  , so its transpose should be an isomorphism
, so its transpose should be an isomorphism  of the dual bundle. This only makes sense if
of the dual bundle. This only makes sense if 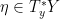 is a covector at y.
is a covector at y.
The above paragraphs are totally obvious, and yet puzzled me for the past three years, until last week when I sat down and decided to work out the details for myself.
The consequence is that we cannot define the symbol of a pseudodifferential operator invariantly. Rather, we declare that a pseudodifferential operator A has the property that for every chart and every pair of cutoffs 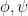 on Y, then the operator
on Y, then the operator  is a pseudodifferential operator on Y (in the sense that it is the quantization of a symbol on Y; here the pushforward
is a pseudodifferential operator on Y (in the sense that it is the quantization of a symbol on Y; here the pushforward  is defined to be the inverse of the pullback
is defined to be the inverse of the pullback  ). Since Y is an open subset of this makes sense.
). Since Y is an open subset of this makes sense.
Previously we have discussed pseudodifferential operators on manifolds M. These can be viewed more abstractly as acting on sections of the trivial line bundle  . However, in geometry one frequently has to deal with sections of more general vector bundles over M. For example, a 1-form is a section of the cotangent bundle. If E, F are vector bundles over M of rank r, s respectively, one may define the Hom-bundle Hom(E, F), which locally is isomorphic to the matrix bundle
. However, in geometry one frequently has to deal with sections of more general vector bundles over M. For example, a 1-form is a section of the cotangent bundle. If E, F are vector bundles over M of rank r, s respectively, one may define the Hom-bundle Hom(E, F), which locally is isomorphic to the matrix bundle  . Then a pseudodifferential operator from sections of E to sections of F is nothing more than a linear map which, after trivialization of E and F, looks like a $s \times r$ matrix of pseudodifferential operators on M. The principal symbol of such an operator sends the cotangent bundle of M into the Hom-bundle Hom(E, F).
. Then a pseudodifferential operator from sections of E to sections of F is nothing more than a linear map which, after trivialization of E and F, looks like a $s \times r$ matrix of pseudodifferential operators on M. The principal symbol of such an operator sends the cotangent bundle of M into the Hom-bundle Hom(E, F).
Wavefront sets.
In this section we will impose that all pseudodifferential operators have Schwartz kernels K such that the projections of supp K are both proper maps. Modulo the space 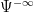 of pseudodifferential operators of order
of pseudodifferential operators of order  , this assumption is no loss of generality. Under this assumption, the top-order term of a symbol — that is, the principal symbol — satisfies the pushforward formula , so the principal symbol is well-defined as an element of
, this assumption is no loss of generality. Under this assumption, the top-order term of a symbol — that is, the principal symbol — satisfies the pushforward formula , so the principal symbol is well-defined as an element of 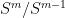 (here
(here 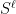 is the
is the 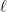 th symbol class). The principal symbol encodes important information about the nature of the operator; for example we have:
th symbol class). The principal symbol encodes important information about the nature of the operator; for example we have:
Definition. An elliptic pseudodifferential operator of order m is one whose principal symbol is  near infinity of each cotangent space.
near infinity of each cotangent space.
The important property is that if A is an elliptic pseudodifferential operator, then A is also invertible modulo the quantization of  . For example the Laplace-Beltrami operator is elliptic on Riemannian manifolds since its symbol is
. For example the Laplace-Beltrami operator is elliptic on Riemannian manifolds since its symbol is 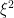 ; since the quadratic form induced by a Lorentzian metric is not positive-definite, it follows that on Lorentzian manifolds, the Laplace-Beltrami operator is not elliptic. Since a Lorentzian Laplace-Beltrami operator is really just the d’Alembertian, whose symbol is
; since the quadratic form induced by a Lorentzian metric is not positive-definite, it follows that on Lorentzian manifolds, the Laplace-Beltrami operator is not elliptic. Since a Lorentzian Laplace-Beltrami operator is really just the d’Alembertian, whose symbol is  , this should be no surprise.
, this should be no surprise.
Recall that a conic set in a vector space is a set which is closed under multiplication by conic scalars. A conic set in a vector bundle, then, is one which is conic in every fiber.
Definition. Let a be the principal symbol of a pseudodifferential operator A of order m. We say that A is noncharacteristic near  if there is a conic neighborhood of
if there is a conic neighborhood of 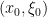 wherein
wherein  near infinity. Otherwise, we say that is a characteristic point. The set of characteristic points is denoted Char A and the set of noncharacteristic points is denoted Ell A.
near infinity. Otherwise, we say that is a characteristic point. The set of characteristic points is denoted Char A and the set of noncharacteristic points is denoted Ell A.
Thus a pseudodifferential operator A is noncharacteristic at 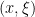 if in a neighborhood of x, A is elliptic when restricted to the direction . By definition, Char A is closed, so we may make the following definition.
if in a neighborhood of x, A is elliptic when restricted to the direction . By definition, Char A is closed, so we may make the following definition.
Definition. Let u be a distribution. The wavefront set WF(u) is the intersection of all sets Char A, where A ranges over pseudodifferential operators such that  .
.
Then WF(u) is a closed conic subset of the cotangent bundle 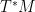 , and its projection to M is exactly the singular support ss(u). Indeed,
, and its projection to M is exactly the singular support ss(u). Indeed,  iff for every pseudodifferential operator A in a sufficiently small neighborhood of x, ; in other words no matter how hard we try, we cannot force u to become singular without differentiating it away from x. The wavefront set also remembers the direction in which this singularity happens; by elliptic invertibility, it will not happen in a direction that A is noncharacteristic.
iff for every pseudodifferential operator A in a sufficiently small neighborhood of x, ; in other words no matter how hard we try, we cannot force u to become singular without differentiating it away from x. The wavefront set also remembers the direction in which this singularity happens; by elliptic invertibility, it will not happen in a direction that A is noncharacteristic.
For example, the only way that  can be made smooth is by cutting off u to away from
can be made smooth is by cutting off u to away from  , which can be done by pseudodifferential operators of order 0 which are elliptic in the x-direction, but not possibly in the y-direction, along the x-axis.
, which can be done by pseudodifferential operators of order 0 which are elliptic in the x-direction, but not possibly in the y-direction, along the x-axis.
Pseudotransport equations.
Hyperbolic operators are meant to generalize the transport equation  . Let us therefore begin by studying the “pseudotransport” equation
. Let us therefore begin by studying the “pseudotransport” equation  .
.
We assume that  is uniformly bounded in
is uniformly bounded in 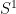 and continuous in
and continuous in 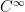 , and the real part of a is uniformly bounded from below. Then we have the energy estimate
, and the real part of a is uniformly bounded from below. Then we have the energy estimate

valid for any  and
and  large enough depending on s. Applying the Hanh-Banach theorem we conclude that for every initial data in
large enough depending on s. Applying the Hanh-Banach theorem we conclude that for every initial data in  we can find
we can find  which solves the pseudotransport equation. In particular, given Schwartz initial data, it follows that u is smooth.
which solves the pseudotransport equation. In particular, given Schwartz initial data, it follows that u is smooth.
Now fix initial data  and assume that the principal symbol exists and is imaginary. (This forces the transport operator to be real and of order 1.) Let q be a symbol of order 0 on space, with principal symbol
and assume that the principal symbol exists and is imaginary. (This forces the transport operator to be real and of order 1.) Let q be a symbol of order 0 on space, with principal symbol  . If in fact Q(D) is a pseudodifferential operator on spacetime such that such at time 0, Q(0) = q, and Q(t, D) commutes with
. If in fact Q(D) is a pseudodifferential operator on spacetime such that such at time 0, Q(0) = q, and Q(t, D) commutes with  then Qu solves the pseudotransport equation. (Actually, we will find Q so that
then Qu solves the pseudotransport equation. (Actually, we will find Q so that ![[Q(t), \partial_t + a(t, x, D_x)]](https://s0.wp.com/latex.php?latex=%5BQ%28t%29%2C+%5Cpartial_t+%2B+a%28t%2C+x%2C+D_x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) is a pseudodifferential operator of order ; this is good enough.) In particular if
is a pseudodifferential operator of order ; this is good enough.) In particular if  then WF(u) is contained in Char Q, and WF(u) should be the intersection of all such sets Char Q.
then WF(u) is contained in Char Q, and WF(u) should be the intersection of all such sets Char Q.
To compute WF(u), let 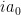 be the principal symbol of a(D) and suppose that
be the principal symbol of a(D) and suppose that 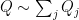 , where
, where 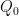 is principal, is given. Then the principal symbol of
is principal, is given. Then the principal symbol of ![[\partial_t + a(t, x, D_x), Q(t, x, D)]](https://s0.wp.com/latex.php?latex=%5B%5Cpartial_t+%2B+a%28t%2C+x%2C+D_x%29%2C+Q%28t%2C+x%2C+D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) is the Poisson bracket
is the Poisson bracket
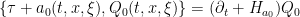
where  is the Hamilton vector field of a symbol p. By inducting on j, we can use this computation to compute
is the Hamilton vector field of a symbol p. By inducting on j, we can use this computation to compute 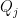 and conclude that modulo an error term of order , we can choose Q to be invariant along the Hamiltonian flow
and conclude that modulo an error term of order , we can choose Q to be invariant along the Hamiltonian flow 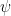 given by the Hamiltonian
given by the Hamiltonian 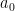 . That is, if
. That is, if 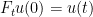 , then
, then  . This result is a sort of “propagation of singularities” for the pseudotransport equation, which generalizes the fact that the transport equation acts on Dirac masses by transporting them, as expected.
. This result is a sort of “propagation of singularities” for the pseudotransport equation, which generalizes the fact that the transport equation acts on Dirac masses by transporting them, as expected.
Solving the hyperbolic Cauchy problem.
Let X be a manifold that represents “spacetime”. A priori we may not have a Lorentzian metric to work with, so instead we fix a function  that is a “time coordinate”. The level surfaces of can be viewed as “spacelike hypersurfaces” in X.
that is a “time coordinate”. The level surfaces of can be viewed as “spacelike hypersurfaces” in X.
Throughout we will let 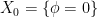 and
and 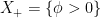 denote the present and future, respectively.
denote the present and future, respectively.
Definition. A hyperbolic operator is a differential operator P of principal symbol p and order m such that  and for every
and for every  such that is not in the span of
such that is not in the span of  , there are m distinct
, there are m distinct 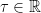 such that
such that 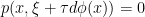 .
.
Since P is a differential operator, p(x) is a homogeneous polynomial of order m. To make sense of the condition, let me restrict to the case that  with its usual Riemannian metric and is the projection onto the t-axis. Then after rotating the first coordinate so that is a covector dual to the x-axis, the condition says that given
with its usual Riemannian metric and is the projection onto the t-axis. Then after rotating the first coordinate so that is a covector dual to the x-axis, the condition says that given  we can find exactly m real numbers
we can find exactly m real numbers  such that
such that  . In the case of the d’Alembertian, we have
. In the case of the d’Alembertian, we have  , and indeed given we can set
, and indeed given we can set 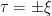 .
.
To state the initial-value problem with initial data in the “initial-time slice” 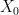 , let v be a vector field such that
, let v be a vector field such that 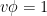 , so v points “forward in time”. The action of v is “differentiating with respect to time”. Note that this hypothesis prevents from degenerating.
, so v points “forward in time”. The action of v is “differentiating with respect to time”. Note that this hypothesis prevents from degenerating.
Theorem (solving the hyperbolic Cauchy problem). Let P be a hyperbolic operator of order m with smooth coefficients, Y a precompact open submanifold of X, and 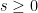 . Assume we are given an inhomogeneous term
. Assume we are given an inhomogeneous term 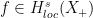 satisfying
satisfying  and initial data
and initial data  , j < m. Then there is
, j < m. Then there is 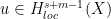 supported in
supported in  such that Pu = f in
such that Pu = f in  and
and  in
in  .
.
The proof is in Chapter 23.2 of Hörmander. The idea is to first prove uniqueness of solutions. By compactness, we may cover Y with finitely many charts U which are isomorphic to open subsets of Minkowski spacetime in which level sets of are spacelike hypersurfaces and orbits of v are worldlines. Since Minkowski spacetime has an honest-to-god time coordinate, the hyperbolicity hypothesis allows us to factor the principal symbol p into first-order factors, and hence factor P into pseudotransport operators on U, at least modulo a lower-order error. We may then apply the solution of the Cauchy problem for pseudotransport operators to solve the Cauchy problem for Pu = f in each chart U, and since there were only finitely many, uniqueness allows us to stitch the local solutions together into a global solution.
The proof outlined in the above paragraph is motivated by the special case when P is the d’Alembertian, which already appears in Chapter 2 of Evans. In that proof, one first observes that the Cauchy problem for the transport equation has an explicit solution. Then one reduces to the case that spacetime is two-dimensional, in which case there is an explicit factorization of P into transport operators, namely  .
.
Propagation of singularities, part I.
To study the propagation of singularities we need to recall some symplectic geometry. Let Q be a pseudodifferential operator on X and q its principal symbol. Then the Hamilton vector field 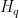 induces a flow on
induces a flow on  which preserves q.
which preserves q.
Definition. The bicharacteristic flow of a pseudodifferential operator Q of principal symbol q is the flow of on  . A bicharacteristic of Q is an orbit of the bicharacteristic flow.
. A bicharacteristic of Q is an orbit of the bicharacteristic flow.
The intuition for the bicharacteristic flow is that its projection to X is “lightlike”, at least if Q is the d’Alembertian.
Theorem (Hörmander’s propagation of singularities). Let P be a pseudodifferential operator of order m such that the Schwartz kernel of P has proper support, and the principal symbol of P is real. Then for every distribution u, WF(u) – WF(f) is invariant under the bicharacteristic flow of P.
By definition of the wavefront set, for every distribution u, WF(u) – WF(Qu) is contained in Char Q. But if Q is a differential operator, then Char Q is exactly the “characteristic variety” , which is exactly the variety where the bicharacteristic flow of Q is defined. Therefore we can ask that WF(u) – WF(Qu) be invariant under the bicharacteristic flow.
If P is a hyperbolic operator of principal symbol p, then the solutions of the equation are all real and distinct, and modulo lower-order terms this can be used to enforce that the coefficients of p are real. We phrase this more simply by saying that the principal symbol of every hyperbolic operator is real.
A partial converse to the reality of principal symbols of hyperbolic operators holds. If Q is a differential operator, then its principal symbol q is a homogeneous polynomial on each cotangent space. Fixing a particular cotangent space, we can write  where
where  ranges over all multiindices of order m and
ranges over all multiindices of order m and  . In order that the characteristic variety of Q have more than one real point, there must be some
. In order that the characteristic variety of Q have more than one real point, there must be some  positive and some negative. But this is exactly the situation of the d’Alembertian, whose principal symbol is
positive and some negative. But this is exactly the situation of the d’Alembertian, whose principal symbol is 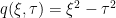 .
.
Thus, while the propagation of singularities theorem only assumes that the principal symbol is real, if the operator P is (for example) elliptic or parabolic, then the conclusion of the theorem is degenerate in the sense that the characteristic variety only has a single real point, so that WF(u) – WF(f) is invariant under EVERY group action on the characteristic variety, not just the bicharacteristic flow.
The interpretation of the propagation of singularities theorem is that P is something like the d’Alembertian, in which case p is something like a Lorentzian metric. The bicharacteristic flow is a flow on the characteristic bundle, which is the space whose points consist of a position x and a lightlike momentum . Therefore the projection of any bicharacteristic to X consists of a worldline. Thus, if the initial data is something like a Dirac mass at x, then the Dirac mass travels along the worldline containing x.
To prove the propagation of singularities theorem, we need a propagation estimate. Recall that if A is a pseudodifferential operator, then WF(A) denotes the microsupport of A; that is, the complement of the largest conic set on which A has order .
Theorem (propagation estimate). Let U be an open conic set, and let 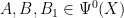 . Let P be a pseudodifferential operator of real principal symbol p and order m.
. Let P be a pseudodifferential operator of real principal symbol p and order m.
For every N > 0 and there is C > 0 such that for every distribution u and every inhomogeneous term f with Pu = f,
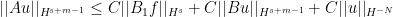
given that the following criteria are met:
- The projection of U is precompact in X.
- For every
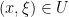 , if
, if  , then and the radial vector field
, then and the radial vector field  are linearly independent at .
are linearly independent at .
- WF(A) and WF(B) are contained in U, while
 .
.
- For every trajectory
 of with
of with  , there is T < 0 such that for every
, there is T < 0 such that for every  ,
,  and
and 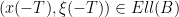 .
.
The term  is an error term created by the use of pseudodifferential operators and is not interesting. The operator
is an error term created by the use of pseudodifferential operators and is not interesting. The operator 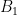 is a cutoff which microlocalizes the problem to a neighborhood to the conic set U. We are interested in WF(u) – WF(f), so we want
is a cutoff which microlocalizes the problem to a neighborhood to the conic set U. We are interested in WF(u) – WF(f), so we want  and
and  . Actually, since we only care about the complement of WF(f), we might as well take f Schwartz, in which case we can take
. Actually, since we only care about the complement of WF(f), we might as well take f Schwartz, in which case we can take  and simplify the propagation estimate to
and simplify the propagation estimate to

The interesting point here is the relationship between the operators A and B. We can optimize the propagation estimate by assuming that WF(B) = Ell B. This is because we really desperately want B to be elliptic on its microsupport, so that it does not introduce any new singularities. Under the assumption WF(B) = Ell B, B is a microlocalization to WF(B), and if  , then got to WF(A) after passing through WF(B). The point is that if u has a singularity at , then (if the regularity exponent s is taken large enough)
, then got to WF(A) after passing through WF(B). The point is that if u has a singularity at , then (if the regularity exponent s is taken large enough)  , but we assumed f Schwartz, so this implies
, but we assumed f Schwartz, so this implies 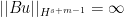 , so that if we traveled back along the bicharacteristic flow from for long enough, we would see that u already had a singularity at some time
, so that if we traveled back along the bicharacteristic flow from for long enough, we would see that u already had a singularity at some time  with T < 0.
with T < 0.
Moreover, the propagation estimate is time-reversible in the sense we can replace T < 0 with -T > 0. Thus the bicharacteristic flow neither creates nor destroys singularities in the distribution u. This readily implies the propagation of singularities theorem.
The proof of the propagation estimate is quite technical and this post is meant as a more of a conceptual discussion so I will omit it.
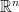
is the measure induced by the symplectic structure on the cotangent bundle and a is the symbol. We also call P a quantization of a.

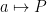
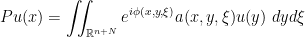
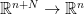

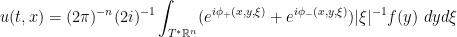

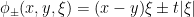
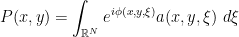

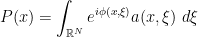
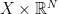


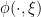
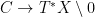
,
, be phases defined in neighborhoods of
which induce a Lagrangian submanifold
of
. Then:
be the signature of the Hessian tensor
. Then
is a locally constant, integer-valued function.
and symbol
, then there exists a symbol
such that A is also an oscillatory integral with phase
and symbol
is the Dirac measure on
. Then modulo lower-order symbols, we have
(1)
to be supported in an arbitrarily small neighborhood of
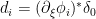
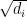
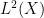
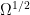
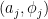
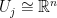

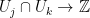

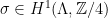
defined on
, we have
.
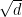

are denoted by
. A canonical relation
is a closed conic Lagrangian submanifold of
with respect to the symplectic form
.
such that the Schwartz kernel of A is an oscillatory integral whose Lagrangian submanifold is C.
is an immersion.

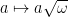
![\gamma: [0, 1] \to M](https://s0.wp.com/latex.php?latex=%5Cgamma%3A+%5B0%2C+1%5D+%5Cto+M&bg=ffffff&fg=000000&s=0&c=20201002) in a surface M such that we can find local coordinates (x, y) for M around some point on the curve, such that in those coordinates we can view
in a surface M such that we can find local coordinates (x, y) for M around some point on the curve, such that in those coordinates we can view 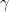 as the parametrization of a continuous nonconstant function F such that
as the parametrization of a continuous nonconstant function F such that  away from a set of Lebesgue measure zero.
away from a set of Lebesgue measure zero.![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . To construct the Cantor set C, we start with a line segment, and split it into equal thirds. We then discard the middle third, leaving us with two equal-length line segments. We iterate this process infinitely many times. Clearly we can identify the points that we’re left with with the paths through a full infinite binary tree, so the Cantor set is uncountable[1].
. To construct the Cantor set C, we start with a line segment, and split it into equal thirds. We then discard the middle third, leaving us with two equal-length line segments. We iterate this process infinitely many times. Clearly we can identify the points that we’re left with with the paths through a full infinite binary tree, so the Cantor set is uncountable[1].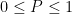 using the Cantor measure. If
using the Cantor measure. If 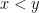 are real numbers, then the Cantor function F is defined by declaring that
are real numbers, then the Cantor function F is defined by declaring that 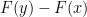 is the probability that
is the probability that  . The standard Devil’s staircase is the graph of the Cantor function.
. The standard Devil’s staircase is the graph of the Cantor function. and there are
and there are  such intervals; it follows that the Cantor set has length at most
such intervals; it follows that the Cantor set has length at most 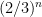 . Since n was arbitrary, the Cantor set has Lebesgue measure zero. Outside the Cantor set, we can explicitly compute
. Since n was arbitrary, the Cantor set has Lebesgue measure zero. Outside the Cantor set, we can explicitly compute 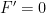 . Since F is a cdf, it is a continuous surjective map
. Since F is a cdf, it is a continuous surjective map ![F: [0, 1] \to [0, 1]](https://s0.wp.com/latex.php?latex=F%3A+%5B0%2C+1%5D+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![[0, 1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002) , we define
, we define ![\int_{[0, 1]^2} X ~d\omega = \int_{\{u \leq 0\}} \nabla \cdot X](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C+1%5D%5E2%7D+X+%7Ed%5Comega+%3D+%5Cint_%7B%5C%7Bu+%5Cleq+0%5C%7D%7D+%5Cnabla+%5Ccdot+X&bg=ffffff&fg=000000&s=0&c=20201002) . Then
. Then ![X \mapsto \int_{[0, 1]^2} X ~d\omega](https://s0.wp.com/latex.php?latex=X+%5Cmapsto+%5Cint_%7B%5B0%2C+1%5D%5E2%7D+X+%7Ed%5Comega&bg=ffffff&fg=000000&s=0&c=20201002) can be shown to be bounded on
can be shown to be bounded on  , so it extends to every continuous vector field on
, so it extends to every continuous vector field on  by the Riesz-Markov representation theorem. On the other hand, the divergence theorem says that if an open set
by the Riesz-Markov representation theorem. On the other hand, the divergence theorem says that if an open set  has a smooth boundary, then
has a smooth boundary, then 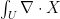 is the integral of the normal part of X to
is the integral of the normal part of X to  . In other words, integrating against
. In other words, integrating against  should represent “integrating the part of the vector field which is normal to the Devil’s staircase”.
should represent “integrating the part of the vector field which is normal to the Devil’s staircase”. of
of  exists for
exists for  must be defined for some x which is not in the horizontal part of the Devil’s staircase. Sharpening
must be defined for some x which is not in the horizontal part of the Devil’s staircase. Sharpening  where
where 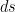 is arc length. So pairing against
is arc length. So pairing against  -dimensional Hausdorff measure of small balls around P. That, in turn, should be computable in terms of the infinite binary string which defines P. But I don’t know how to do that. I’d love to talk about this problem with you, if you do have an idea.
-dimensional Hausdorff measure of small balls around P. That, in turn, should be computable in terms of the infinite binary string which defines P. But I don’t know how to do that. I’d love to talk about this problem with you, if you do have an idea. ,
, 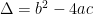 .
. are undefined at the time that they are used, while the variable
are undefined at the time that they are used, while the variable 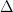 is supposed to be the discriminant of
is supposed to be the discriminant of  -plane cut out by the equation
-plane cut out by the equation 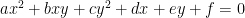 where
where 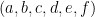 are constants. So this isn’t too egregious but it is still an error, and in more complicated arguments could potentially be a serious issue.
are constants. So this isn’t too egregious but it is still an error, and in more complicated arguments could potentially be a serious issue. be a
be a  -dimensional vector space. For every
-dimensional vector space. For every 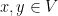 , define
, define  .
.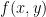 is the cross-product, or the wedge product, or the polynomial product, or the tensor product, or some other kind of product, of
is the cross-product, or the wedge product, or the polynomial product, or the tensor product, or some other kind of product, of 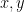 . But we don’t know which product it is! Indeed,
. But we don’t know which product it is! Indeed,  , and for every
, and for every  for the cross product of
for the cross product of  .
. is a function, and for every
is a function, and for every 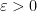 we can find a
we can find a  such that for any
such that for any  such that
such that  ,
,  .
.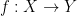 be a function. Then there is some
be a function. Then there is some  in the image of
in the image of  is allowed to be the empty set, in which case
is allowed to be the empty set, in which case  .
.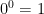 , which is problematic because it means that the function
, which is problematic because it means that the function 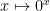 is not continuous (since if
is not continuous (since if  then
then 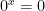 ).
). . Then let
. Then let 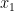 to
to 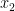 .
.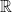 . Then the supremum of
. Then the supremum of 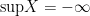 . In most cases, the reaction would be “So what? It’s just an edge case error.” But actually, in my case, I later discovered that the thing I was trying to prove was only interesting in the case that
. In most cases, the reaction would be “So what? It’s just an edge case error.” But actually, in my case, I later discovered that the thing I was trying to prove was only interesting in the case that 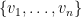 is a basis of the vector space
is a basis of the vector space  , which proves our claim.
, which proves our claim.![F: [0, 1] \to X](https://s0.wp.com/latex.php?latex=F%3A+%5B0%2C+1%5D+%5Cto+X&bg=ffffff&fg=000000&s=0&c=20201002) be a bounded measurable function. Then we can find a sequence
be a bounded measurable function. Then we can find a sequence  of simple measurable functions such that
of simple measurable functions such that 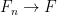 almost everywhere pointwise and
almost everywhere pointwise and  .
. doesn’t depend on the choice of
doesn’t depend on the choice of  be a finite abelian group, and let
be a finite abelian group, and let 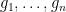 be a minimal set of generators of
be a minimal set of generators of 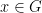 there are unique
there are unique 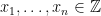 such that
such that  .
.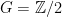 ,
, 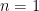 ,
, 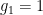 , and
, and  , because we can write
, because we can write 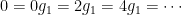 . So, when generalizing a theory, one does need to be really careful that they haven’t “imported” a false theorem to higher generality! (There’s no shame in making this mistake, though; I think that many mathematicians tried to prove Fermat’s Last Theorem but committed this error by assuming that unique factorization would hold in certain rings — after all, unique factorization holds in everyone’s favorite ring
. So, when generalizing a theory, one does need to be really careful that they haven’t “imported” a false theorem to higher generality! (There’s no shame in making this mistake, though; I think that many mathematicians tried to prove Fermat’s Last Theorem but committed this error by assuming that unique factorization would hold in certain rings — after all, unique factorization holds in everyone’s favorite ring 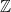 — that it fails in.)
— that it fails in.)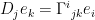 . Here and always we use Einstein’s convention.
. Here and always we use Einstein’s convention.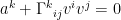 , which to mathematicians is more popularly known as the geodesic equation. It says that the “acceleration” in the coordinate frame e is entirely due to the fact that e itself is an accelerated frame.
, which to mathematicians is more popularly known as the geodesic equation. It says that the “acceleration” in the coordinate frame e is entirely due to the fact that e itself is an accelerated frame. as a bilinear form, we can rewrite Newton’s first law as
as a bilinear form, we can rewrite Newton’s first law as  , which now resembles Newton’s second law with unit mass. Indeed, the acceleration of the particle is given exactly by a quantity
, which now resembles Newton’s second law with unit mass. Indeed, the acceleration of the particle is given exactly by a quantity  which can be reasonably interpreted as a “force”. For example, one could consider the case that the spatial origin is a particle P which is orbiting around a point. If one believes that P really is “inertial”, then they will measure a fictitious force — the centrifugal force — acting on all objects. In general relativity, moreover, I think that the notion of “inertial” is ill-defined. In this case, if v is timelike then $\Gamma^k(v, v)$ is the acceleration due to gravity. In particular these fictitious forces all scale linearly with mass, because the geodesic equation does not have a mass factor and so we need to cancel out the factor of mass in the law
which can be reasonably interpreted as a “force”. For example, one could consider the case that the spatial origin is a particle P which is orbiting around a point. If one believes that P really is “inertial”, then they will measure a fictitious force — the centrifugal force — acting on all objects. In general relativity, moreover, I think that the notion of “inertial” is ill-defined. In this case, if v is timelike then $\Gamma^k(v, v)$ is the acceleration due to gravity. In particular these fictitious forces all scale linearly with mass, because the geodesic equation does not have a mass factor and so we need to cancel out the factor of mass in the law 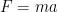 .
. as a quadratic form valued in the tangent space. In other words it is tempting to think of
as a quadratic form valued in the tangent space. In other words it is tempting to think of  as a section of
as a section of 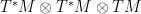 . This of course presupposes that M has a trivial tangent bundle, since the Christoffel symbols are only defined locally. Putting our doubts aside, this is equivalent to thinking of
. This of course presupposes that M has a trivial tangent bundle, since the Christoffel symbols are only defined locally. Putting our doubts aside, this is equivalent to thinking of 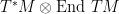 .
.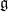 as both subsets of End E, whenever E is a G-bundle. By a gauge transformation of a G-bundle E one means a section of End E which is in fact a section of G. Thus gauge transformations act on E (and so also on End E, etc.)
as both subsets of End E, whenever E is a G-bundle. By a gauge transformation of a G-bundle E one means a section of End E which is in fact a section of G. Thus gauge transformations act on E (and so also on End E, etc.) but in fact are sections of
but in fact are sections of  . (Briefly, the Christoffel symbols are
. (Briefly, the Christoffel symbols are 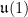 -valued 1-forms — in other words, imaginary 1-forms. A gauge transformation, then, is defined by adding an imaginary exact 1-form to the Christoffel symbols. We interpret the Christoffel symbols A as (i times) potentials for the electromagnetic field. In fact, one can take the exterior derivative of A and obtain a closed 2-form
-valued 1-forms — in other words, imaginary 1-forms. A gauge transformation, then, is defined by adding an imaginary exact 1-form to the Christoffel symbols. We interpret the Christoffel symbols A as (i times) potentials for the electromagnetic field. In fact, one can take the exterior derivative of A and obtain a closed 2-form  , which one can view as the Faraday tensor. The fact that one can add an exact 1-form to A is exactly the gauge invariance of the Maxwell equation
, which one can view as the Faraday tensor. The fact that one can add an exact 1-form to A is exactly the gauge invariance of the Maxwell equation  where j is the current 1-form.
where j is the current 1-form.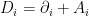 . So for a function u (i.e. a section of the trivial bundle E) on M,
. So for a function u (i.e. a section of the trivial bundle E) on M, 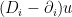 weights u according to the strength of the electromagnetic potential. This is mainly interesting when u is a constant function, in which case
weights u according to the strength of the electromagnetic potential. This is mainly interesting when u is a constant function, in which case 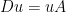 is the potential rescaled by u.
is the potential rescaled by u. or
or 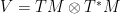 above). In any particular case they should have a nice physical interpretation but I don’t think one can interpret the Maxwell-Yang-Mills case and the Levi-Civita case as one and the same.
above). In any particular case they should have a nice physical interpretation but I don’t think one can interpret the Maxwell-Yang-Mills case and the Levi-Civita case as one and the same. , namely the fact that every linear operator has an eigenvalue, that every linear operator has a unique Jordan canonical form, and the Cayley-Hamilton theorem. In all of these cases, one could prove the theorem using determinants, but there’s no good reason to, since there is a perfectly reasonable structure theory of linear operators over
, namely the fact that every linear operator has an eigenvalue, that every linear operator has a unique Jordan canonical form, and the Cayley-Hamilton theorem. In all of these cases, one could prove the theorem using determinants, but there’s no good reason to, since there is a perfectly reasonable structure theory of linear operators over  , which is the case for most of the results in the latter half of the book, except for one single chapter about the structure theory over
, which is the case for most of the results in the latter half of the book, except for one single chapter about the structure theory over 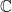 . But I do think that a lot of the angry comments I’ve seen about the book on Reddit and elsewhere, which mainly focus on the issue of determinants, are just totally out to lunch.)
. But I do think that a lot of the angry comments I’ve seen about the book on Reddit and elsewhere, which mainly focus on the issue of determinants, are just totally out to lunch.)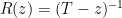 of the linear operator T acting on a vector space V of dimension n, which is a rational map from
of the linear operator T acting on a vector space V of dimension n, which is a rational map from  to a space of matrices. Clearly an eigenvalue is a pole of R, and the number of poles equals the number of zeroes (this is clearly true when
to a space of matrices. Clearly an eigenvalue is a pole of R, and the number of poles equals the number of zeroes (this is clearly true when 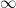 , T must have n eigenvalues. (If
, T must have n eigenvalues. (If  counted with multiplicity. If
counted with multiplicity. If 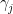 around the puncture of
around the puncture of  and define
and define 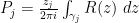 and similarly
and similarly 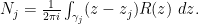 It is now a straightforward consequence of Cauchy’s integral formula that
It is now a straightforward consequence of Cauchy’s integral formula that 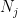 is nilpotent and we have
is nilpotent and we have  . Furthermore, if
. Furthermore, if  is the image of
is the image of  , then A acts on
, then A acts on  , and we have a direct sum decomposition
, and we have a direct sum decomposition 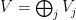 . That implies that
. That implies that 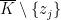 , and replacing the differential form
, and replacing the differential form  with some sort of algebraic analogue of cohomology.
with some sort of algebraic analogue of cohomology. . This argument ostensibly works over
. This argument ostensibly works over 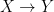 where Y is a compact Hausdorff space. By Alexandroff’s theorem, X always has a compactification, but in general if X is not compact then X may have multiple compactifications. We consider the category Comp X of compactifications of X equipped with continuous surjections which preserve X; the Alexandroff compactification is the final object of Comp X.
where Y is a compact Hausdorff space. By Alexandroff’s theorem, X always has a compactification, but in general if X is not compact then X may have multiple compactifications. We consider the category Comp X of compactifications of X equipped with continuous surjections which preserve X; the Alexandroff compactification is the final object of Comp X. where
where 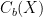 is the Banach space of bounded continuous functions on X with its supremum norm, and the functor Spec is taken in the sense of C*-algebras (thus Spec A consists of maximal closed ideals equipped with the Zariski-Jacobson topology). This proof is presumably inoffensive to anyone who accepts ZFC (and offensive to anyone who does not, since one needs Zorn’s lemma to show that
is the Banach space of bounded continuous functions on X with its supremum norm, and the functor Spec is taken in the sense of C*-algebras (thus Spec A consists of maximal closed ideals equipped with the Zariski-Jacobson topology). This proof is presumably inoffensive to anyone who accepts ZFC (and offensive to anyone who does not, since one needs Zorn’s lemma to show that 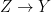 is a morphism in Comp X, then since X is dense in Z, the underlying continuous surjection
is a morphism in Comp X, then since X is dense in Z, the underlying continuous surjection 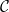 be a chain in Comp X; then
be a chain in Comp X; then  . Since
. Since  is a compact Hausdorff space by Tychonoff’s theorem, so is C. Taking the inverse limits of the open dense embeddings
is a compact Hausdorff space by Tychonoff’s theorem, so is C. Taking the inverse limits of the open dense embeddings  , we obtain an open dense embedding
, we obtain an open dense embedding  , so C is an upper bound of
, so C is an upper bound of  is a large category. To see that Comp X is equivalent to a small category, it suffices to show that there is a cardinal
is a large category. To see that Comp X is equivalent to a small category, it suffices to show that there is a cardinal  such that every compactification of Comp X has at most
such that every compactification of Comp X has at most 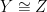 in Comp X, and the set-theoretic rank of Z is at most
in Comp X, and the set-theoretic rank of Z is at most 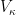 . Furthermore, if Y is a compactification of X and
. Furthermore, if Y is a compactification of X and 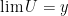 . Since Y is Hausdorff, it follows that y is the UNIQUE limit of U, but some cardinal arithmetic can be used to show that if
. Since Y is Hausdorff, it follows that y is the UNIQUE limit of U, but some cardinal arithmetic can be used to show that if  ultrafilters on Open X (since elements of an ultrafilter on Open X are open subsets of X), so the cardinality of Y is at most
ultrafilters on Open X (since elements of an ultrafilter on Open X are open subsets of X), so the cardinality of Y is at most  .
. be a regular cardinal. We say that
be a regular cardinal. We say that  is an inaccessible cardinal if for every cardinal
is an inaccessible cardinal if for every cardinal  ,
,  . We say that
. We say that  such that
such that  .
. . Then there are inaccessible cardinals
. Then there are inaccessible cardinals  . If
. If  and Y is a compactification of X, then Y can be obtained as an extension of the Alexandroff compactification by splitting nets, but
and Y is a compactification of X, then Y can be obtained as an extension of the Alexandroff compactification by splitting nets, but 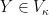 . Therefore
. Therefore  is a small category in
is a small category in 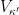 , so X has a Stone–Čech compactification
, so X has a Stone–Čech compactification 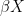 with
with 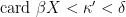 .
. , references to which we will suppress when possible. Let
, references to which we will suppress when possible. Let

 is a fine sheaf, i.e. it has partitions of unity subordinate to every open cover, then
is a fine sheaf, i.e. it has partitions of unity subordinate to every open cover, then 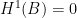 and the long exact sequence collapses to the exact sequence
and the long exact sequence collapses to the exact sequence
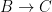 induces a bounded linear map
induces a bounded linear map  such that
such that  is the kernel of
is the kernel of  and
and 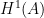 is the cokernel of
is the cokernel of  satisfies
satisfies
 denote the sheaf of holomorphic functions on
denote the sheaf of holomorphic functions on  the Cauchy-Riemann operator. Let
the Cauchy-Riemann operator. Let  denote the sheaf of smooth functions on
denote the sheaf of smooth functions on  , for
, for 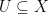 open, induces a short exact sequence of sheaves of Fréchet spaces
open, induces a short exact sequence of sheaves of Fréchet spaces

 is by definition the genus
is by definition the genus  of
of 
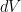 on
on  norm on
norm on 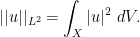
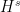 clashes with the notation for cohomology, so let me use
clashes with the notation for cohomology, so let me use 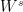 to denote the completion of
to denote the completion of 
 ranges over multiindices. Then
ranges over multiindices. Then 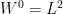 and
and  . The kernel of
. The kernel of 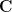 , by Liouville’s theorem and Weyl’s lemma), so to deduce that
, by Liouville’s theorem and Weyl’s lemma), so to deduce that 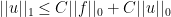
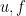 which satisfy
which satisfy  . By definition of the Sobolev norm, we have
. By definition of the Sobolev norm, we have
 is smooth. Then we can write
is smooth. Then we can write  where
where  and
and 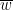 are holomorphic. In particular,
are holomorphic. In particular, 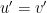 and
and  , so
, so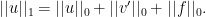
 . Taking a Cauchy estimate, we see that
. Taking a Cauchy estimate, we see that

 be a sequence in
be a sequence in 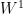 with
with  , and assume that the
, and assume that the  are Cauchy in
are Cauchy in  . Without loss of generality we may assume that
. Without loss of generality we may assume that 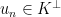 where
where  is the kernel of
is the kernel of 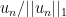 , and thus assume that they are in fact bounded. By the Rellich-Kondrachov theorem (which says that the natural map
, and thus assume that they are in fact bounded. By the Rellich-Kondrachov theorem (which says that the natural map 
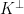 , hence the
, hence the  of
of 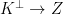 . Therefore
. Therefore 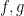 ,
,
 . Since
. Since  is closed, the dual of the cokernel of
is closed, the dual of the cokernel of  of
of 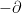 ; by the Rellich-Kondrachov theorem, the unit ball of
; by the Rellich-Kondrachov theorem, the unit ball of  of degree
of degree  . Then the equation
. Then the equation  has
has  , counting multiplicity.
, counting multiplicity. is a real closed field, but since there are lots of real closed fields, one usually defines
is a real closed field, but since there are lots of real closed fields, one usually defines  such that
such that 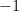 does not have a square root in
does not have a square root in  . As usual, we want to show that
. As usual, we want to show that  is constant.
is constant. is finite. Therefore
is finite. Therefore 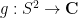 , by stereographic projection. Also by stereographic projection, one can cover the sphere by two copies of
, by stereographic projection. Also by stereographic projection, one can cover the sphere by two copies of  , one centered at the south pole that misses only the north pole, and one centered at the north pole that only misses the south pole. Thus one can define the Laplacian,
, one centered at the south pole that misses only the north pole, and one centered at the north pole that only misses the south pole. Thus one can define the Laplacian, 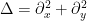 , in each of these coordinates; it remains well-defined on the overlaps of the charts, so
, in each of these coordinates; it remains well-defined on the overlaps of the charts, so  . (In fancy terminology, which may help people who already know ten different proofs of the fundamental theorem of algebra but will not enlighten anyone else, we view
. (In fancy terminology, which may help people who already know ten different proofs of the fundamental theorem of algebra but will not enlighten anyone else, we view  is called harmonic provided that
is called harmonic provided that  . We claim that
. We claim that  where
where  . Then
. Then  exactly if
exactly if  be a sequence in [0, 1] that we want to show has a convergent subsequence. Let
be a sequence in [0, 1] that we want to show has a convergent subsequence. Let  and let
and let ![I_1 = [0, 1]](https://s0.wp.com/latex.php?latex=I_1+%3D+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. such that
such that 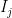 is a subinterval of
is a subinterval of  of half length and there is a subsequence of
of half length and there is a subsequence of  . By the pigeonhole principle, since there are infinitely many points of
. By the pigeonhole principle, since there are infinitely many points of  and let
and let 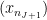 be the first point of
be the first point of 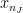 in
in  of
of 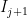 is half of
is half of 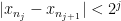 . That implies that
. That implies that  .
.![x \in [0, 1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore
. Therefore ![K = [0, 1]^n](https://s0.wp.com/latex.php?latex=K+%3D+%5B0%2C+1%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002) be a box. We claim that K is compact. To see this, let $(x_n)$ be a sequence in K. If n = 1, then $(x_n)$ has a convergent subsequence.
be a box. We claim that K is compact. To see this, let $(x_n)$ be a sequence in K. If n = 1, then $(x_n)$ has a convergent subsequence.![[0, 1]^{n-1}](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D%5E%7Bn-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) is compact. Then we can write
is compact. Then we can write  where
where ![y_n \in [0, 1]^{n-1}](https://s0.wp.com/latex.php?latex=y_n+%5Cin+%5B0%2C+1%5D%5E%7Bn-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![z_n \in [0, 1]](https://s0.wp.com/latex.php?latex=z_n+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . So there is a convergent subsequence
. So there is a convergent subsequence  . Now
. Now 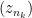 has a convergent subsequence
has a convergent subsequence  , and then
, and then  is a convergent subsequence. So K is compact.
is a convergent subsequence. So K is compact.![L = [-R, R]^n](https://s0.wp.com/latex.php?latex=L+%3D+%5B-R%2C+R%5D%5En&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that  . Without loss of generality, assume that R = 1.
. Without loss of generality, assume that R = 1.