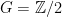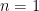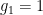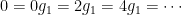Recently, both through grading proofs and trying to teach some new math majors how to write proofs, I’ve had the opportunity to see a lot of invalid proofs. I want to record here some of the more common errors that invalidate an argument here.
Compilation errors. When grading a huge stack of problem sets, I kind of feel like a compiler. I go through each argument and stop once I run into an error. If I can guess what the author meant to say, I throw a warning (i.e. take off points) but continue reading; otherwise, I crash (i.e. mark the proof wrong).
So by a compilation error, I just mean an error in which the student had an argument which is probably valid in their heads, but when they wrote it down, they mixed up quantifiers, used an undefined term, wrote something syntactically invalid, or similar. I believe that these are the most common errors. Here are some examples of sentences in proofs that I would consider as committing a compilation error:
For a conic section
,
.
Here the variable 

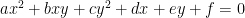
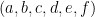
There’s another thing problematic about this example. We use “For” without a modifier “For every” or “For some”. Does just one conic section satisfy the equation
Let
Here’s another compilation error:
Let
be a
-dimensional vector space. For every
, define
.
Here the author probably means that 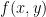
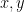
Let
, and for every
for the cross product of
We have seen that compilation errors are usually just caused by sloppiness. That doesn’t mean that compilation errors can’t point to a more serious problem with one’s proof — they could, for example, obscure a key step in the argument which is actually fatally flawed. Arguably, this is the case with Shinichi Mochizuki’s infamous incorrect proof of Szpiro’s Conjecture. However, I think that most beginners can avoid compilation errors by making sure that they define every variable before using it, are never ambiguous about if they mean “for every” or “for some”, and otherwise just being very careful in their writing. And beginners should avoid using symbol-soup whenever possible, in favor of the English language. If you ever write something like
Suppose that
.
I will probably take off points, even though I can, in principle, parse what you’re trying to say. The reason is that you could just as well write
Suppose that
is a function, and for every
we can find a
such that for any
such that
,
.
which is much easier to read.
Edge-case errors. An edge-case error is an error in a proof, where the proof manages to cover every case except for a single special case where the proof fails. These errors are also often caused by sloppiness, but are more likely to actually be a serious flaw in an argument than a compilation error. They also tend to be a lot harder to detect than compilation errors. Here’s an example:
Let
be a function. Then there is some
in the image of
.
Do you see the problem? Don’t read ahead until you try to find it for a few minutes.
Okay, first of all, if you read ahead without trying to find the problem, shame on you; second of all, if you’ve written something like this, don’t feel shame, because it’s a common mistake. The issue, of course, is that 

Most of the time the empty function isn’t too big of an issue, but it can come up sometimes. For example, the fact that the empty function exists means that arguably 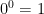
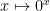

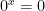
Here’s an example from topology:
Let
. Then let
be a path from
to
.
In practice, most spaces we care about are quite nice — manifolds, varieties, CW-complexes, whatever. In such spaces, if they are connected we can find a path between any two points. However, this is not true in general, and the famous counterexample is the topologist’s sine curve. The point is that it’s very important to make sure you get your assumptions right — if you wrote this in a proof there’s a good chance it would cause the rest of the argument to fail, unless you had an additional assumption that the space
In general, a good strategy to avoid errors like the above error is to beware of the standard counterexamples of whatever area of math you are currently working in, and make sure none of them can sneak past your argument! One way to think about this is to imagine that you are Alice, and Bob is handing you the best counterexamples he can find for your argument. You can only beat Bob if you can demonstrate that none of his counterexamples actually work.
Let me also give an example from my own work.
Let
. Then the supremum of
It sure looks like this statement is true, since 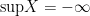
Fatal errors. These are errors which immediately cause the entire argument to fail. If they can be patched, so much the better, but unlike the other two types of errors that can usually be worked around, a fatal error often cannot be repaired.
The most common fatal error I see in beginners’ proofs is the circular argument, as in the below example:
We claim that every vector space is finite-dimensional. In fact, if
is a basis of the vector space
, which proves our claim.
If you read a standard textbook on linear algebra, they will certainly assume that given a vector space
(This is not to say that there are almost-circular arguments which do prove something nontrivial. Induction is a form of this, as is the closely related “proof by a priori estimate” technique used in differential equations. But if one looks closely at these arguments they will see that they are not, in fact, circular.)
The other kind of fatal error is similar: there’s some sneaky assumption used in the proof, which isn’t really an edge case assumption. I have blogged about an insidious such assumption, namely the continuum hypothesis. In general, these assumptions often are related to edge-case issues, but may even happen in the generic case, as you mentally make an assumption that you forget to keep track of. Here is another example, also from measure theory:
Let
be a bounded measurable function. Then we can find a sequence
of simple measurable functions such that
almost everywhere pointwise and
.
This definition looks like the standard definition of an integral in any measure theory course. However, without a stronger assumption on 
This sort of fatal error is particularly tricky to deal with when one is first learning a more general version of a familiar theory. Most undergraduates are familiar with linear algebra, and the fact that every finite-dimensional vector space has a basis. In particular, every element of a vector space can be written uniquely in terms of a given basis. So when one first learns about finite abelian groups, they might be tempted to write:
Let
be a finite abelian group, and let
be a minimal set of generators of
there are unique
such that
.
In fact, the counterexample here is