The central dogma of geometry is that a space X is the “same” data as the functions on X, i.e. the functions  for R some ring. In analysis, of course, we usually take R to be the real numbers, or an algebra over the real numbers. Some examples of this phenomenon:
for R some ring. In analysis, of course, we usually take R to be the real numbers, or an algebra over the real numbers. Some examples of this phenomenon:
- A smooth manifold X is determined up to smooth diffeomorphism by the sheaf of rings of smooth functions from open subsets of X into
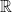 .
.
- An open subset X of the Riemann sphere is determined up to conformal transformation is determined by the algebra of holomorphic functions
 .
.
- An algebraic variety X over a field K is determined up to isomorphism by the sheaf of rings of polynomial functions from Zariski open subsets of X into K.
- The example we will focus on in this post: a compact Hausdorff space X is determined by the C*-algebra of continuous functions .
In the above we have always assumed that the ring R was commutative, and in fact a field. As a consequence the algebra A of functions is also commutative. If we view A as “the same data” as X, then there should be some generalization of the notion of a space that corresponds to when A is noncommutative. I learned how to do this for compact Hausdorff spaces when I took a course on C*-algebras last semester, and I’d like to describe this generalization of the notion of compact Hausdorff space here.
Fix a Hilbert space H, and let B(H) be the algebra of bounded linear operators on H. By a C*-algebra acting on H, we mean a complex subalgebra of B(H) which is closed under taking adjoints and closed with respect to the operator norm. In case  for some measure space X, we will refer to C*-algebras acting on H as C*-algebras on X.
for some measure space X, we will refer to C*-algebras acting on H as C*-algebras on X.
In case X is a compact Hausdorff space, there are three natural C*-algebras on X. First is B(H) itself; second is the algebra 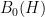 of compact operators acting on H (in other words, the norm-closure of finite rank operators), and third is the C*-algebra C(X) of continuous functions on X, which acts on H by pointwise multiplication. The algebra C(X) is of course commutative.
of compact operators acting on H (in other words, the norm-closure of finite rank operators), and third is the C*-algebra C(X) of continuous functions on X, which acts on H by pointwise multiplication. The algebra C(X) is of course commutative.
If A is a commutative, unital C*-algebra and I is a maximal ideal in A, then A/I is a field, and by the Gelfand-Mazur theorem in fact  . It follows that the maximal spectrum (i.e. the set of maximal ideals) of A is in natural bijection with the space of continuous, surjective algebra morphisms
. It follows that the maximal spectrum (i.e. the set of maximal ideals) of A is in natural bijection with the space of continuous, surjective algebra morphisms  ; namely, I corresponds to the projection
; namely, I corresponds to the projection  . In particular I is closed. One can show that every such morphism has norm 1, so lies in the unit ball of the dual space A*; and that the limit of a net of morphisms in the weakstar topology is also a morphism. Therefore the weakstar topology of A* restricts to the maximal spectrum of A, which is then a compact Hausdorff space by the Banach-Alaoglu theorem.
. In particular I is closed. One can show that every such morphism has norm 1, so lies in the unit ball of the dual space A*; and that the limit of a net of morphisms in the weakstar topology is also a morphism. Therefore the weakstar topology of A* restricts to the maximal spectrum of A, which is then a compact Hausdorff space by the Banach-Alaoglu theorem.
If A = C(X), then the maximal spectrum of A consists of the ideals 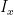 of functions f such that
of functions f such that 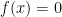 , where
, where  . The projections
. The projections 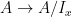 are exactly of the form
are exactly of the form 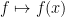 . This is the content of the baby Gelfand-Naimark theorem: the maximal spectrum of C(X) is X, and conversely every commutative, unital C*-algebra arises this way. (The great Gelfand-Naimark theorem, on the other hand, guarantees that every C*-algebra, defined as a special kind of ring rather than analytically, is a C*-algebra acting [faithfully] on a Hilbert space as I defined above.) The baby Gelfand-Naimark theorem is far from constructive; the proof of the Banach-Alaoglu theorem requires the axiom of choice, especially when A is not separable.
. This is the content of the baby Gelfand-Naimark theorem: the maximal spectrum of C(X) is X, and conversely every commutative, unital C*-algebra arises this way. (The great Gelfand-Naimark theorem, on the other hand, guarantees that every C*-algebra, defined as a special kind of ring rather than analytically, is a C*-algebra acting [faithfully] on a Hilbert space as I defined above.) The baby Gelfand-Naimark theorem is far from constructive; the proof of the Banach-Alaoglu theorem requires the axiom of choice, especially when A is not separable.
Let us briefly run through the properties of X that we can easily recover from C(X). Continuous maps 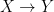 correspond to continuous, unital algebra morphisms
correspond to continuous, unital algebra morphisms  ; a map f is sent to the morphism which pulls back functions along f. Points, as noted above, correspond to maximal ideals. If K is a closed subset of X and I is the ideal of functions that vanish on K, then A/I is the “localization” of A at I. (So inclusions of compact Hausdorff spaces correspond to projections of C*-algebras.)
; a map f is sent to the morphism which pulls back functions along f. Points, as noted above, correspond to maximal ideals. If K is a closed subset of X and I is the ideal of functions that vanish on K, then A/I is the “localization” of A at I. (So inclusions of compact Hausdorff spaces correspond to projections of C*-algebras.)
If X is just locally compact, then the C*-algebra  of continuous functions on X which vanish at the fringe of every compactification of X is not unital (since 1 does not vanish at the fringe), and the unital algebras A which extend correspond to compact Hausdorff spaces that contain X, in a sort of “Galois correspondence”. In fact, the one-point compactification of X corresponds to the minimal unital C*-algebra containing , while the Stone-Cech compactification corresponds to the C*-algebra
of continuous functions on X which vanish at the fringe of every compactification of X is not unital (since 1 does not vanish at the fringe), and the unital algebras A which extend correspond to compact Hausdorff spaces that contain X, in a sort of “Galois correspondence”. In fact, the one-point compactification of X corresponds to the minimal unital C*-algebra containing , while the Stone-Cech compactification corresponds to the C*-algebra 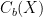 of bounded continuous functions on X. Therefore the compactifications of X correspond to the unital C*-algebras A such that
of bounded continuous functions on X. Therefore the compactifications of X correspond to the unital C*-algebras A such that 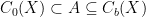 , and surjective continuous functions which preserve the compactification structure, say
, and surjective continuous functions which preserve the compactification structure, say 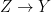 , correspond to the inclusion maps
, correspond to the inclusion maps  . Two examples of this phenomenon:
. Two examples of this phenomenon:
- The C*-algebra
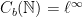 has a maximal spectrum whose points are exactly the ultrafilters on
has a maximal spectrum whose points are exactly the ultrafilters on  . In particular
. In particular  has a maximal spectrum whose points are exactly the free ultrafilters. This is why we needed the axiom of choice so badly.
has a maximal spectrum whose points are exactly the free ultrafilters. This is why we needed the axiom of choice so badly.
- The compactification of obtained as the C*-algebra generated by
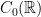 and $\theta \mapsto e^{i\theta}$ is a funny-looking curve in
and $\theta \mapsto e^{i\theta}$ is a funny-looking curve in 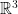 . Try drawing it! (As a hint: think of certain spaces which are connected but not path-connected…)
. Try drawing it! (As a hint: think of certain spaces which are connected but not path-connected…)
If  is a metric space, then we can recover the metric d from its Lipschitz seminorm L. This is the seminorm
is a metric space, then we can recover the metric d from its Lipschitz seminorm L. This is the seminorm  , which is finite exactly if f is Lipschitz. One then has
, which is finite exactly if f is Lipschitz. One then has  . The Lipschitz seminorm also satisfies the identities
. The Lipschitz seminorm also satisfies the identities 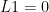 , and
, and  , the latter being known as the Leibniz axiom. A seminorm
, the latter being known as the Leibniz axiom. A seminorm 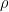 satisfying these properties gives rise to a metric on X, and if the resulting topology on X is actually the topology of X, we say that is a Lip-norm.
satisfying these properties gives rise to a metric on X, and if the resulting topology on X is actually the topology of X, we say that is a Lip-norm.
Finally, if  is a continuous vector bundle, then let
is a continuous vector bundle, then let  denote the vector space of continuous sections of E. Then is a projective module over C(X), and Swan’s theorem says that every projective module arises this way. Moreover, the module structure of determines E up to isomorphism.
denote the vector space of continuous sections of E. Then is a projective module over C(X), and Swan’s theorem says that every projective module arises this way. Moreover, the module structure of determines E up to isomorphism.
So now we have all we need to consider noncommutative compact Hausdorff spaces. By such a thing, I just mean a unital C*-algebra A, which I will call X when I am thinking of it as a space. Since A is noncommutative, we cannot appeal to the Gelfand-Mazur theorem, and in fact the notion of a maximal ideal doesn’t quite make sense. The correct generalization of maximal ideal is known as a “primitive ideal”: an ideal I is primitive if I is the annihilator of a simple A-module. (The only simple A-module is 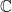 if A is commutative, so in that case I is maximal.) The primitive spectrum of A admits a Zariski topology, which coincides with the weakstar topology when A is commutative. So the points of X will consist of primitive ideals of A. Metrics on X will be Lip-norms; vector bundles will be projective modules.
if A is commutative, so in that case I is maximal.) The primitive spectrum of A admits a Zariski topology, which coincides with the weakstar topology when A is commutative. So the points of X will consist of primitive ideals of A. Metrics on X will be Lip-norms; vector bundles will be projective modules.
What of functions? We already know that elements of A should be functions on X. But what is their codomain? Clearly not a field — they aren’t commutative! If I is a primitive ideal corresponding to a point x, we let 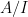 be the localization at x. This will be some C*-algebra, which is a simple module
be the localization at x. This will be some C*-algebra, which is a simple module  that we view as the ring that functions send x into. (So this construction may send different points into different rings — this isn’t so different from algebraic geometry, however, where localization at an integer n sends points of
that we view as the ring that functions send x into. (So this construction may send different points into different rings — this isn’t so different from algebraic geometry, however, where localization at an integer n sends points of  into the ring
into the ring  .) Matrix rings are simple, so often will be a matrix ring.
.) Matrix rings are simple, so often will be a matrix ring.
Let’s run through an example of a noncommutative space. Let T be the unit circle in $\mathbb R^2$. The group $\mathbb Z/2$ acts on T by  . This corresponds to an action on the C*-algebra C(T) by
. This corresponds to an action on the C*-algebra C(T) by  . Whenever a group G acts on a C*-algebra B, we can define a semidirect product
. Whenever a group G acts on a C*-algebra B, we can define a semidirect product  , and so we let our C*-algebra A be the semidirect product
, and so we let our C*-algebra A be the semidirect product  . It turns out that A is the C*-algebra generated by unitary operators that form a group isomorphic to
. It turns out that A is the C*-algebra generated by unitary operators that form a group isomorphic to 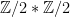 , where
, where  is the coproduct of groups.
is the coproduct of groups.
We may express elements of A as f + gb, where b is the nontrivial element of 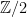 and
and  ; A is a C*-algebra acting on L^2(T) by
; A is a C*-algebra acting on L^2(T) by  , for any
, for any  . The center Z(A) of A, therefore, consists of
. The center Z(A) of A, therefore, consists of  such that
such that  . Therefore Z(A) is isomorphic to the C*-algebra
. Therefore Z(A) is isomorphic to the C*-algebra ![C([-1, 1])](https://s0.wp.com/latex.php?latex=C%28%5B-1%2C+1%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  is sent to
is sent to  (where
(where  , and the choice of sign does not matter by assumption on f).
, and the choice of sign does not matter by assumption on f).
The spectrum of Z(A) is easy to compute, therefore: it is just [-1, 1]! For every ![x \in [-1, 1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , let
, let  be “localization at x”, where is the ideal generated by which vanish at x. Now let
be “localization at x”, where is the ideal generated by which vanish at x. Now let  ; one then has a morphism of C*-algebras
; one then has a morphism of C*-algebras  by $f + gb \mapsto \frac{1}{2}\begin{bmatrix}f(e^{i\theta})&g(e^{i\theta})\\g(e^{-i\theta})&f(e^{-i\theta})\end{bmatrix}$. This morphism is always injective, and if
by $f + gb \mapsto \frac{1}{2}\begin{bmatrix}f(e^{i\theta})&g(e^{i\theta})\\g(e^{-i\theta})&f(e^{-i\theta})\end{bmatrix}$. This morphism is always injective, and if  , it is also surjective. Therefore
, it is also surjective. Therefore 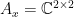 in that case. Since
in that case. Since  is a simple ring, it follows that the spectrum of A contains x.
is a simple ring, it follows that the spectrum of A contains x.
But something funny happens at the end-points, corresponding to the fact that  were fixed points of . Since
were fixed points of . Since 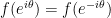 in that case and similarly for g, is isomorphic to the 2-dimensional subalgebra of consisting of symmetric matrices with a doubled diagonal entry. This is not a simple module, and in fact projects onto in two different ways; therefore there are two points in the spectrum of A corresponding to each of
in that case and similarly for g, is isomorphic to the 2-dimensional subalgebra of consisting of symmetric matrices with a doubled diagonal entry. This is not a simple module, and in fact projects onto in two different ways; therefore there are two points in the spectrum of A corresponding to each of 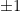 !
!
Thus the primitive ideal space X of A is not Hausdorff; in fact it looks like [-1, 1], except that the end-points are doubled. This is similar to the “bug-eyed line” phenomenon in algebraic geometry.
What is the use of such a space? Well, Qiaochu Yuan describes a proof (that I believe is due to Marc Rieffel), using this space X, that if B is any C*-algebra and  are projections such that
are projections such that 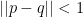 , then there is a unitary operator u such that
, then there is a unitary operator u such that  at MathOverflow. The idea is that p, q actually project onto generators of the C*-algebra
at MathOverflow. The idea is that p, q actually project onto generators of the C*-algebra 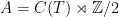 , using the fact that A is also generated by .
, using the fact that A is also generated by .
As a consequence, in any separable C*-algebra, there are only countably many projections. Thus one may view the above discussion as a very overcomplicated, long-winded proof of the fact that  is not separable.
is not separable.

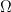

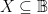
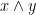








,
.
, there is a unique
(“not
and
.
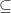
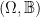
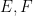


![\mu: \mathbb B \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmu%3A+%5Cmathbb+B+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

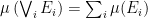








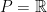

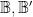




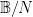






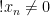
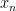
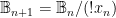



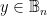


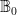



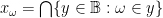
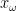
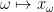

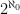







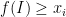



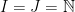
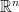 is compact; the converse is easy, so this proves the Heine-Borel theorem.
is compact; the converse is easy, so this proves the Heine-Borel theorem. guests, either
guests, either  of real numbers has a monotone subsequence. This completes the proof, since any bounded monotone sequence is Cauchy.
of real numbers has a monotone subsequence. This completes the proof, since any bounded monotone sequence is Cauchy. are friends if
are friends if 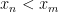 ; otherwise, say they are strangers. By the infinite Ramsey theorem, there is an infinite set
; otherwise, say they are strangers. By the infinite Ramsey theorem, there is an infinite set 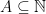 such that either all elements of A are friends, or all elements of A are strangers. Passing to the subsequence indexed by A, we find a subsequence consisting only of friends (in which case it is increasing) or of strangers (in which case it either has a subsequence which is constant, or a subsequence which is decreasing).
such that either all elements of A are friends, or all elements of A are strangers. Passing to the subsequence indexed by A, we find a subsequence consisting only of friends (in which case it is increasing) or of strangers (in which case it either has a subsequence which is constant, or a subsequence which is decreasing). is an uncountable cardinal such that for every party with
is an uncountable cardinal such that for every party with  . (Actually, we could replace mu by any Bernoulli measure, but this is slightly cleaner.) This measure mu extends to the Borel sets of C.
. (Actually, we could replace mu by any Bernoulli measure, but this is slightly cleaner.) This measure mu extends to the Borel sets of C.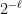 , and in particular appears at least once.
, and in particular appears at least once. .) Clearly T is measure-preserving. Now define a Borel function
.) Clearly T is measure-preserving. Now define a Borel function 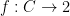 by projection onto the first factor:
by projection onto the first factor:  . Then
. Then  and obviously the expected value of f is 1/2. So by the ergodic theorem, the frequency of 0 in x is the expected value of f, so we are done.
and obviously the expected value of f is 1/2. So by the ergodic theorem, the frequency of 0 in x is the expected value of f, so we are done.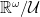 , where
, where 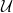 is a free ultrafilter on the powerset
is a free ultrafilter on the powerset  of
of  (so we identify the measure with the set of all sets which it sends to 1). Of course atomic ultrafilters on
(so we identify the measure with the set of all sets which it sends to 1). Of course atomic ultrafilters on  be an infinite set, k an ordered field, and
be an infinite set, k an ordered field, and 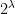 . (This can be defined in much greater generality than ordered fields, but that’s all we’ll need for our purposes.) As usual
. (This can be defined in much greater generality than ordered fields, but that’s all we’ll need for our purposes.) As usual 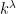 is the set of all maps
is the set of all maps  (so if
(so if 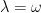 , it is the sequence space of k). Now
, it is the sequence space of k). Now  , by declaring that two maps x and y are equivalent if they are equal almost everywhere. The resulting quotient is known as the ultrapower
, by declaring that two maps x and y are equivalent if they are equal almost everywhere. The resulting quotient is known as the ultrapower 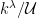 of k.
of k. lift to pointwise operations on
lift to pointwise operations on  of Lebesgue-almost everywhere equivalence classes p-integrable functions by taking quotients of operations on the space
of Lebesgue-almost everywhere equivalence classes p-integrable functions by taking quotients of operations on the space  of p-integrable functions. Finally, we declare
of p-integrable functions. Finally, we declare 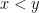 if
if  for almost every
for almost every 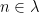 .
.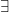 ,
, 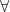 ,
, 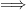 ,
,  (i.e. “not”), +,
(i.e. “not”), +, 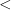 , =, 0, 1, and parentheses and variables, where
, =, 0, 1, and parentheses and variables, where  means that there exists an element
means that there exists an element  exists is a formula, namely
exists is a formula, namely  . A more sophisticated example of a formula is the quadratic formula, as would be a nice exercise to verify. We need infinitely many formulae to express that k is characteristic 0, namely
. A more sophisticated example of a formula is the quadratic formula, as would be a nice exercise to verify. We need infinitely many formulae to express that k is characteristic 0, namely 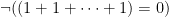 for every length of 1’s. And we cannot express that k is archimedean even with infinitely many formulae.
for every length of 1’s. And we cannot express that k is archimedean even with infinitely many formulae. is any ultrapower of k, then for every formula
is any ultrapower of k, then for every formula 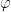 that is true in k,
that is true in k,  , then
, then 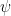 is true almost everywhere iff
is true almost everywhere iff  . If
. If  be such that a satisfies
be such that a satisfies  satisfying
satisfying  in the image of
in the image of 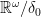 , then the map
, then the map  is an isomorphism
is an isomorphism  , so we have not shown the existence of infinitesimals. This is why we assumed that the ultrafilter
, so we have not shown the existence of infinitesimals. This is why we assumed that the ultrafilter 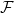 to be a measure on a subalgebra
to be a measure on a subalgebra 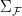 of
of  if there is an inclusion of algebras
if there is an inclusion of algebras 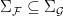 , and
, and  if they agree whenever both are defined, just like in the proof of the Hanh-Banach theorem. By taking limits we see that the supremum of filters is a filter. Now we apply Zorn’s lemma to the space of free filters, which is easily seen to be an ultrafilter.
if they agree whenever both are defined, just like in the proof of the Hanh-Banach theorem. By taking limits we see that the supremum of filters is a filter. Now we apply Zorn’s lemma to the space of free filters, which is easily seen to be an ultrafilter. , descends to an positive element
, descends to an positive element  of
of 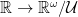 is not an isomorphism, as desired.
is not an isomorphism, as desired. . The completion of the span of the sequence
. The completion of the span of the sequence  be a Baire group and
be a Baire group and  be a Polish group, and
be a Polish group, and  be a (possibly discontinuous) morphism of groups. If, for every open set
be a (possibly discontinuous) morphism of groups. If, for every open set 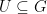 ,
, 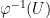 has the property of Baire, then
has the property of Baire, then  has the property of Baire, so f is continuous by Pettis’s theorem.
has the property of Baire, so f is continuous by Pettis’s theorem. individuals, each of which are either infected with Disease X or not. On day
individuals, each of which are either infected with Disease X or not. On day  , individual
, individual  has probability
has probability ![\beta_{ij}(t) \in [0, 1]](https://s0.wp.com/latex.php?latex=%5Cbeta_%7Bij%7D%28t%29+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002) of infecting individual
of infecting individual  with Disease X. Besides, individual
with Disease X. Besides, individual  of death, which depends on the age of
of death, which depends on the age of 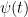 .
. existed if individual
existed if individual  (defined to be the expected number of new infections from infected individual
(defined to be the expected number of new infections from infected individual  divided by
divided by  be an index set
be an index set  (which we shall assume
(which we shall assume  for simplicity) and let
for simplicity) and let  be probability spaces.
be probability spaces.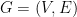 (whose vertices are indexed by
(whose vertices are indexed by  if for the graph
if for the graph  and each edge
and each edge 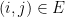 we associate random variables
we associate random variables 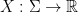 ,
,  ,
,  .
.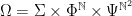 , the product taken in the sense of measure spaces. Then a decoration is nothing more than a random variable
, the product taken in the sense of measure spaces. Then a decoration is nothing more than a random variable 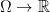 . We interpret decorations as referring to the variables
. We interpret decorations as referring to the variables  , etc. described above.
, etc. described above. be the category of random graphs which have been decorated by
be the category of random graphs which have been decorated by  is a stochastic graph if
is a stochastic graph if  is deterministic (i.e. there is a fixed graph
is deterministic (i.e. there is a fixed graph  , which we call the initial data, such that for each
, which we call the initial data, such that for each 
 almost surely).
almost surely).  as an assignment which takes the decoration
as an assignment which takes the decoration  of
of 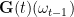 and returns the random graph
and returns the random graph  (so that at time
(so that at time  , the random graph is “parametrized by the decorations of time
, the random graph is “parametrized by the decorations of time  “).
“). but did you know that
but did you know that  ?
?